通过夜莺监控etcd
ETCD 是 Kubernetes 控制面的重要组件和依赖,k8s中各个组件的信息都存储在etcd中,因此监控etcd也很重要
ETCD 的数据采集通常使用 3 种方式
- 使用 ETCD 所在宿主的 agent 直接来采集,因为 ETCD 是个静态 Pod,所以 agent 直接连上去采集即可
- 把采集器和 ETCD 做成 sidecar 的模式
- 使用服务发现机制,在中心端部署采集器,与采集apiserver、controller-manager一样
etcd内置了/metrics接口,通过2379端口可以用来获取指标数据,但是访问是需要证书的,如图:

通过kubeadm安装的集群,证书位置一般在/etc/kubernetes/pki/etcd路径下,通过证书以及categraf的prometheus插件即可获取数据
除了2379端口外,etcd还提供了2381这个端口用来获取指标数据,此端口不需要证书,查看etcd.yaml,如图:
cat /etc/kubernetes/manifests/etcd.yaml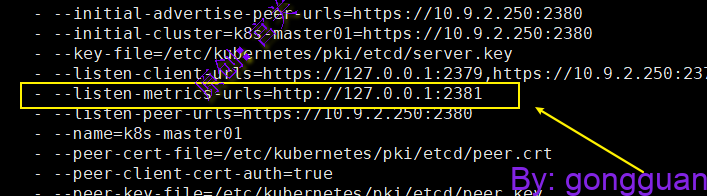
通过此地址测试发现已经可以采集到数据,注意是http,如图:
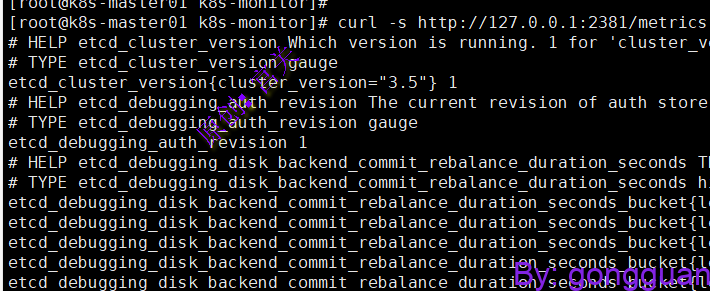
1、本例子中依然通过服务发现机制来采集数据,继续修改采集apiserver和controller时用的prometheus.yml文件,添加etcd相关内容,如下:
- job_name: 'etcd'
kubernetes_sd_configs:
- role: endpoints
scheme: http
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;etcd;http
注意:上图中的source_labels的三个值,对应的就是下面regex的三个值,命名空间为kube-system,服务名为etcd,ep的端口名为http
2、上述例子中的服务名etcd和endpoint的端口名并不存在,因此需要新建,如下:
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: etcd
labels:
k8s-app: etcd
spec:
selector:
component: etcd #标签是安装etcd时就已经自带的了
type: ClusterIP
clusterIP: None
ports:
- name: http
port: 2381
targetPort: 2381
protocol: TCP
2、修改etcd配置文件地址,改为0.0.0.0,如图:
vim /etc/kubernetes/manifests/etcd.yaml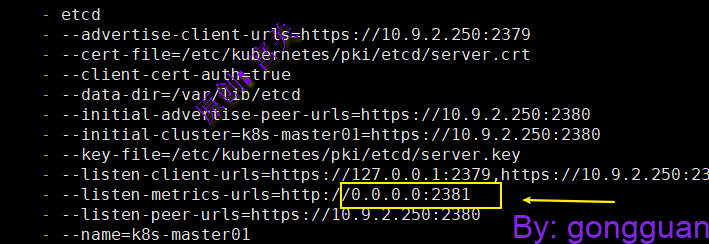
3、重启prometheus agent mode的pod,并且应用资源文件,如下:
kubectl rollout restart deploy prometheus-agent -n monitor
kubectl apply -f prometheus.yml
4、在夜莺控制面板即时查询里查看监控指标,如图:
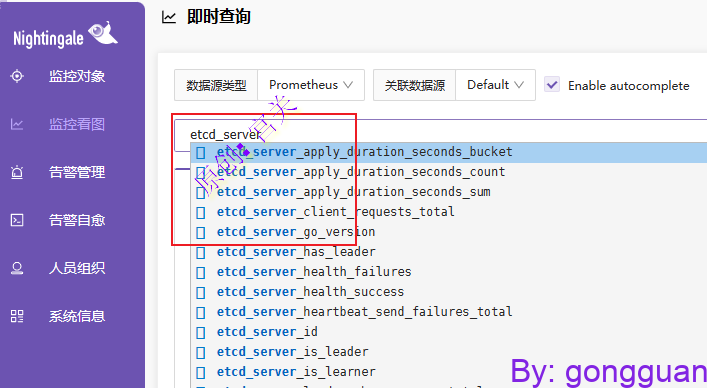
注:如果没有指标,可检查prometheus agent 容器内部/etc/prometheus/prometheus.yml中的etcd配置是否加载进来(通过configMap挂载进去的)
附加:
如果有多个相同的监控指标,可根据job名字区分,如图:
关键指标如下:
# HELP etcd_server_is_leader Whether or not this member is a leader. 1 if is, 0 otherwise.
# TYPE etcd_server_is_leader gauge
etcd leader 表示 ,1 leader 0 learner
# HELP etcd_server_health_success The total number of successful health checks
# TYPE etcd_server_health_success counter
etcd server 健康检查成功次数
# HELP etcd_server_health_failures The total number of failed health checks
# TYPE etcd_server_health_failures counter
etcd server 健康检查失败次数
# HELP etcd_disk_defrag_inflight Whether or not defrag is active on the member. 1 means active, 0 means not.
# TYPE etcd_disk_defrag_inflight gauge
是否启动数据压缩,1表示压缩,0表示没有启动压缩
# HELP etcd_server_snapshot_apply_in_progress_total 1 if the server is applying the incoming snapshot. 0 if none.
# TYPE etcd_server_snapshot_apply_in_progress_total gauge
是否再快照中,1 快照中,0 没有
# HELP etcd_server_leader_changes_seen_total The number of leader changes seen.
# TYPE etcd_server_leader_changes_seen_total counter
集群leader切换的次数
# HELP grpc_server_handled_total Total number of RPCs completed on the server, regardless of success or failure.
# TYPE grpc_server_handled_total counter
grpc 调用总数
# HELP etcd_disk_wal_fsync_duration_seconds The latency distributions of fsync called by WAL.
# TYPE etcd_disk_wal_fsync_duration_seconds histogram
etcd wal同步耗时
# HELP etcd_server_proposals_failed_total The total number of failed proposals seen.
# TYPE etcd_server_proposals_failed_total counter
etcd proposal(提议)失败总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_proposals_pending The current number of pending proposals to commit.
# TYPE etcd_server_proposals_pending gauge
etcd proposal(提议)pending总次数(proposal就是完成raft协议的一次请求)
# HELP etcd_server_read_indexes_failed_total The total number of failed read indexes seen.
# TYPE etcd_server_read_indexes_failed_total counter
读取索引失败的次数统计(v3索引为所有key都建了索引,索引是为了加快range操作)
# HELP etcd_server_slow_read_indexes_total The total number of pending read indexes not in sync with leader's or timed out read index requests.
# TYPE etcd_server_slow_read_indexes_total counter
读取到过期索引或者读取超时的次数
# HELP etcd_server_quota_backend_bytes Current backend storage quota size in bytes.
# TYPE etcd_server_quota_backend_bytes gauge
当前后端的存储quota(db大小的上限)
通过参数quota-backend-bytes调整大小,默认2G,官方建议不超过8G
# HELP etcd_mvcc_db_total_size_in_bytes Total size of the underlying database physically allocated in bytes.
# TYPE etcd_mvcc_db_total_size_in_bytes gauge
etcd 分配的db大小(使用量大小+空闲大小)
# HELP etcd_mvcc_db_total_size_in_use_in_bytes Total size of the underlying database logically in use in bytes.
# TYPE etcd_mvcc_db_total_size_in_use_in_bytes gauge
etcd db的使用量大小
# HELP etcd_mvcc_range_total Total number of ranges seen by this member.
# TYPE etcd_mvcc_range_total counter
etcd执行range的数量
# HELP etcd_mvcc_put_total Total number of puts seen by this member.
# TYPE etcd_mvcc_put_total counter
etcd执行put的数量
# HELP etcd_mvcc_txn_total Total number of txns seen by this member.
# TYPE etcd_mvcc_txn_total counter
etcd实例执行事务的数量
# HELP etcd_mvcc_delete_total Total number of deletes seen by this member.
# TYPE etcd_mvcc_delete_total counter
etcd实例执行delete操作的数量
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
etcd cpu使用量
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
etcd 内存使用量
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
etcd 打开的fd数目

