分布式存储之ceph原理与部署
一、ceph简介:
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
官方文档地址:
https://docs.ceph.com/en/nautilus/start/
二、ceph特点:
1、高性能:
- 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
- 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- 能够支持上千个存储节点的规模,支持TB到PB级的数据
2、高可用性 :
- 副本数可以灵活控制
- 支持故障域分隔,数据强一致性
- 多种故障场景自动进行修复自愈
- 没有单点故障,自动管理。
3、高可扩展性 :
- 去中心化
- 扩展灵活
- 随着节点增加而线性增长
4、 特性丰富:
- 支持三种存储接口:块存储、文件存储、对象存储
- 支持自定义接口,支持多种语言驱动
三、ceph核心组件介绍:
- Monitor: 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据
- Managers: Ceph 管理器 (守护进程ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。
- OSD: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数),OSD本质上就是一个个host主机上的存储磁盘
- MDS: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令
- Object : Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据
- PG: PG全称Placement Groups(归置组),是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据
- RADOS : RADOS全称Reliable Autonomic Distributed Object Store(可靠的自主分布式对象存储),是Ceph集群的精华,用户实现数据分配、Failover(故障转移)等集群操作
- Libradio : Librados是Rados提供库,可以理解为请求的api,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持
- CRUSH : CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方
- RBD : RBD全称RADOS block device,是Ceph对外提供的块设备服务
- RGW : RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容
- CephFS : CephFS全称Ceph File System,是Ceph对外提供的文件系统服务
- Pool:pool 是Ceph存储时的逻辑分区,它起到namespace的作用
1、关于pool(存储池)
在ceph上,存储池(pool) 将RADOS存储集群提供的存储服务逻辑分割一个或多个存储区域,可以理解为数据对象的名称空间,管理员可以为特定应用程序存储不同类型数据的需求分别创建专用的存储池,例如rbd存储池、rgw存储池等,也可以为某个项目或某个用户创建专有的存储池,如果一个存储池里面的数据过多,为了方便管理,还可以进一步细分为一至多个名称空间(namespace),客户端(包括rbd和rgw等)存取数据时,需要事先指定存储池名称、用户名和密钥等信息完成认证,而后将一直维持与其指定的存储池的连接,于是也可以把存储池看作是客户端的IO接口
存储池有两种类型;默认情况下,我们不指定什么类型的存储池就是副本池(replicated pool);所谓副本池就是存储在该存储之上的对象数据,都会由RADOS集群将每个对象数据在集群中存储为多个副本,其中存储于主OSD的为主副本,副本数量在创建存储池时 由管理员指定;默认情况下不指定副本数量,对应副本数量为3个,即1主2从,存储一份对象数据时,为了冗余备份,需要将数据存储3分,即有两份冗余;此时磁盘利用率也只有1/3,为了提高磁盘的利用率的同时,又能保证冗余,ceph还支持纠删码池(erasure code)
纠删码池就是把对象存储为 N=K+M 个块,其中,K为数据块数量,M为编码块数量,因此存储池的尺寸为 K+M ;纠删码是一种前向纠错(FEC)代码通过将K块的数据转换为N块,假设N=K+M,则其中的M代表纠删码算法添加的额外或冗余的块数量以提供冗余机制(即编码块),而N则表示在纠删码编码之后要创建的块的总数,其可以故障的总块数为M(即N-K)个;类似RAID5;纠删码池减少了确保数据持久性所需的磁盘空间量,但计算量上却比副本存储池要更贵一些;但我们在使用纠删码池的时候需要注意不是所有的应用都支持纠删码池,比如,RGW可以使用纠删码存储池,但RBD就不支持纠删码池,它只支持副本池
2、关于PG
PG是一个虚拟概念,用来存放object,pgp相当于pg存放的一种osd排列组合
官方建议的PG使用数量:
- 集群中小于5个OSD,则设置PG的数量为128
- 集群有5-10个OSD时,设置PG的数量为512
- 集群中有10-50个OSD时,设置PG的数量为1024
- 如果集群osd大于50个,设置PG数量为 (osd数量 * 100) / 3
举例如下:
(1)、首先创建一个包含6个pg的存储池temp-pool,并设置副本为2,如下:
ceph osd pool create temp-pool 6
ceph osd pool set temp-pool size 2查看pg在osd中的分布情况,如图:
ceph pg dump pgs |awk ‘{print $1,$19}’ #查看分布情况命令
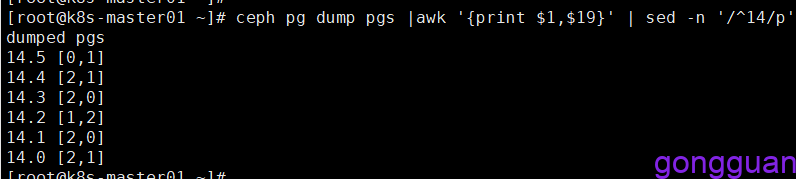
由于存储池为2个副本,池中共有6个pg,因此每个pg都会分布在两个osd上,一个为主,一个为备份,整个集群中只有3个osd,因此将会有6中排列方式,一个osd可以承载多个pg,因此会有不同的pg分配到同一个osd中,上图中pg有6个,在3个osd上共有6中排列方式,此时pgp也为6
四、三种存储类型:
1、块存储(RBD):
典型设备: 磁盘阵列、硬盘, 主要是将裸磁盘空间映射给主机使用的,需要格式化才可以使用
优点:
- 通过Raid与LVM等手段,对数据提供了保护
- 多块廉价的硬盘组合起来,提高容量
- 多块磁盘组合出来的逻辑盘,提升读写效率
缺点:
- 采用SAN架构组网时,光纤交换机,造价成本高
- 主机之间无法共享数据,相当于本地盘,只能在本机使用
2、文件存储(CephFS):
典型设备: FTP、NFS服务器, 为了克服块存储文件无法共享的问题,所以有了文件存储, 在服务器上架设FTP与NFS服务,就是文件存储
优点:
- 造价低,随便一台机器即可
- 方便文件共享
缺点:
- 读写速率低
- 传输速率慢
注:一个ceph集群中只能有一个CephFS,创建多个会报错
3、对象存储(RGW):
典型设备: 内置大容量硬盘的分布式服务器(swift, s3) , 多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能
优点:
- 具备块存储的读写高速特性
- 具备文件存储的共享等特性
总结:块存储读写快,但是不能共享,文件存储读写慢但是可以共享,对象存储结合两者有点,读写快也能共享
注意:Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )
五、存储原理:
Ceph的底层是RADOS(Reliable Automatic Distributed Object Store,可靠的自动分布式对象存储),RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现,存储过程如下:

从上图可以看出, 无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects), Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,ino即是文件的File ID,用于在全局唯一标识每一个文件,而ono则是分片的编号。比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。Oid的好处是可以唯一标识每个不同的对象,并且存储了对象与文件的从属关系。由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高
但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的;并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。为了解决这些问题,ceph引入了归置组的概念,即PG
PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。
注:一个PG可以管理若干个object(对象),但是一个对象只能映射到一个PG中,一对多关系
那么对象时如何映射进PG的?还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量取模,得到的序号则是PGID。由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布。
最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
注:一个PG可以映射到多个OSD上,每个OSD可以承载若干PG,多对多关系

上图中更好的诠释了ceph数据流的存储过程,数据无论是从三中接口哪一种写入的,最终都要切分成对象存储到底层的RADOS中。逻辑上通过算法先映射到PG上,最终存储近OSD节点里, 图中除了之前介绍过的概念之外多了一个pools的概念
Pool是管理员自定义的命名空间,像其他的命名空间一样,用来隔离对象与PG。我们在调用API存储即使用对象存储时,需要指定对象要存储进哪一个POOL中。POOL中管理若干PG,实际是将object映射到PG中,除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据清洗次数、数据块及对象大小等

存储数据总结:
首先将客户端存储的对象数据切分多个固定大小的对象数据,然后将这些固定大小的数据对象通过一致性hash算法将对象数据映射至存储池里的PG,然后由CRUSH算法计算以后,再将PG映射至对应osd,然后由mon返回osd的ID给客户端,客户端拿着mon给的osd相关信息主动联系对应osd所在节点osd进程,进行数据存储操作。
六、部署:
环境准备:
| 机器IP | 系统 |
| 192.168.72.128(mon,mgr,ceph-deploy) | centos7 |
| 192.168.72.129(mon,mgr) | centos7 |
| 192.168.72.130(mon,mgr) | centos7 |
注:ceph-deploy可以单独部署在一台机器
1、关闭防火墙和selinux:
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config2、修改三台机器的主机名:
hostnamectl set-hostname ceph1 //192.168.72.128
hostnamectl set-hostname ceph2 //192.168.72.129
hostnamectl set-hostname ceph3 //192.168.72.130在每台机器上修改/etc/hosts文件:
192.168.72.128 ceph1
192.168.72.129 ceph2
192.168.72.130 ceph33、配置免密登录:
#在ceph1上执行如下命令,一路回车即可(也可以选择其他节点)
ssh-keygen
#将公钥发送到其他节点
ssh-copy-id 192.168.72.129
ssh-copy-id 192.168.72.1304、三台机器配置yum源:
#CentOS 7 源设置
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#epel 仓库源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo编辑Ceph.repo,添加内容如下:
cat > /etc/yum.repos.d/Ceph.repo << EOF
[ceph-nautilus]
name=ceph-nautilus
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
[ceph-nautilus-noarch]
name=ceph-nautilus-noarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
EOF#生成缓存
yum clean all
yum makecache5、ntp服务器安装:
#三台机器都执行安装命令
yum install ntp -y在主节点配置连接时间服务器,其余节点从主节点同步时间
在主节点192.168.72.128机器上执行命令如下:
#同步国家ntp时间服务器
ntpdate -u cn.pool.ntp.org
#添加到定时任务中
00 10 * * * /usr/sbin/ntpdate -u cn.pool.ntp.org > /dev/null 2>&1; /sbin/hwclock -w
#修改 /etc/ntp.conf文件
#注释下面4行
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#新增下面两行
server 127.127.1.0
fudge 127.127.1.0 stratum 10
#重启ntpd
systemctl restart ntpd查看主节点的ntp服务器是否为自身,执行命令ntpq -p ,输出如下内容表示已经配置成功,如图:

其余节点执行命令如下:
#修改 /etc/ntp.conf文件
#注释下面4行
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#新增下面两行
server 192.168.72.128 //注意:此地址为主节点地址
fudge 127.127.1.0 stratum 10
#重启ntpd
systemctl restart ntpd其余节点重启ntpd完成后执行命令如下命令检查,显示如下内容表示成功,如图:

6、安装ceph:
在所有上都安装ceph,主节点上额外安装ceph-deploy(实际是通过ceph-deploy来部署集群)
#每个主机安装 ceph
yum install ceph -y
#主节点额外安装ceph-deploy,不支持centos8
yum install ceph-deploy -y7、部署集群
#在主节点上创建目录,后面的ceph-deploy命令都要在此目录下执行才可以,否则报错找不到ceph.conf
mkdir -p /root/ceph && cd /root/ceph
#执行命令开始部署新的集群
ceph-deploy new ceph1 ceph2 ceph3
#执行完成后当前目录会生成三个文件:ceph.conf、ceph-deploy-ceph.log、ceph.mon.keyring
#上述命令执行后,会在每个节点的/etc/ceph路径下生成三个文件ceph.conf rbdmap tmplp2KgF8、部署监控节点(mon):
#yum安装的ceph默认在/var/lib/ceph下,设置属主和属组
chown ceph:ceph -R /var/lib/ceph
#进入目录
cd /root/ceph
#执行命令部署mon(必须当前目录有ceph.mon.keyring)
ceph-deploy mon create-initial
#最后执行命令启动mon,注意@后面的为主机名
systemctl status ceph-mon@ceph1mon之间使用6789端口通信
注意:mon部署完成后,在每台机器上都可以看到mon进程(systemctl status ceph-mon@ceph2/3)
9、部署mgr(建议每台mon节点都部署一个,保证高可用):
#在主节点执行命令如下:
cd /root/ceph //进入ceph.conf所在目录
ceph-deploy mgr create ceph1 ceph2 ceph3
#在ceph2机器上执行命令启动mgr
systemctl start/stop/restart ceph-mgr@ceph2
#ps -ef |grep mgr可查看进程部署完成后,在三个节点都可以看到mgr进程,如图:
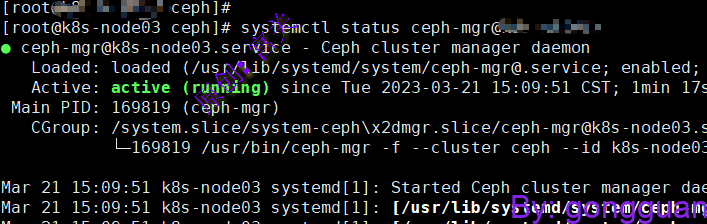
注:启用ceph-mgr之后集群状态才会是HEALTH_OK
10、部署OSD:
用系统盘也可以但是不安全,建议用挂在盘,有两种方案:
- 用其他新机器来部署osd
- 通过本地额外挂载盘(本例子通过此方式)
首先给机器添加硬盘,只添加就可以,不用fdisk来格式化,添加后执行如下操作:
#硬盘添加完成后执行fdisk -l可以查看到硬盘设备,本例子中为/dev/sdb
#执行命令创建osd,本例子创建三个osd
ceph-deploy --overwrite-conf osd create --data /dev/sdb ceph1
ceph-deploy --overwrite-conf osd create --data /dev/sdb ceph2
ceph-deploy --overwrite-conf osd create --data /dev/sdb ceph3
#将/root/ceph/目录下的ceph.client.admin.keyring、ceph.conf 复制到三台机器的/etc/ceph下,这样三台机器都可以执行管理命令
\cp -a /root/ceph/ceph.client.admin.keyring ceph.conf /etc/ceph/
#执行命令查看硬盘树编号,如下图
ceph osd tree
执行命令启动三台机器上的osd,如下:
#注意:下面的0,1,2对应上图中的编号osd.0中的0,1,2
systemctl start ceph-osd@0
systemctl start ceph-osd@1
systemctl start ceph-osd@212、部署RGW
#单机的只需要在一台服务器上安装, 如果负载均衡,可以安装3台服务器
yum install ceph-radosgw -y
#或者
ceph-deploy install --rgw ceph1 ceph2 ceph3执行如下命令启动rgw,如下:
#先进去/root/ceph目录,命令都要在此路径下执行因为要读取文件
cd /root/ceph
ceph-deploy rgw create ceph1
ceph-deploy rgw create ceph2
ceph-deploy rgw create ceph3
或者
ceph-deploy rgw create ceph1 ceph2 ceph3
#查看与启停命令
systemctl status/start/stop/restart ceph-radosgw@rgw.ceph1
systemctl status/start/stop/restart ceph-radosgw@rgw.ceph2
systemctl status/start/stop/restart ceph-radosgw@rgw.ceph3注意:如果在执行的时候出现错误:[ERROR ] RuntimeError: command returned non-zero exit status,此时可将/etc/yum.repos.d目录下的epel.repo和epel-testing.repo先删除或者命名成别的文件
13、部署mds(只有使用CephFS的时候才需要部署)
#如果提示ceph.conf已经存在需要覆盖,那么就在ceph-deploy后加参数--overwrite-conf
ceph-deploy mds create ceph1 ceph2 ceph3安装完成后,在三个节点都可以看到mds集成,可通过如下命令管理mds,如下:
systemctl start/stop/status/restart ceph-mds@ceph114、创建账号(s3)
#system参数是为了使用dashboard,该账号可以再页面上看到数据,只有加了--system参数的账号才可以启动RGW功能
#执行命令如下,newid和gongguan为自定义
radosgw-admin user create --uid newid --display-name 'gongguan' --system
#执行完成后记住access_key和secret_key
"access_key": "2EU1430P7ZJTUD8UXSRG",
"secret_key": "hnwx36TQCLLwtmR00nLJWklGKUZ8tTKrAGyAk2i7"
15、部署dashboard:
#在mgr节点执行如下命令:如果有多个mgr,那么每个节点下都要安装
yum install ceph-mgr-dashboard -y
#开启插件
ceph mgr module enable dashboard --force
ceph mgr module ls | grep dashboard
#创建自签证书,在主节点/root/ceph路径下
cd /root/ceph
ceph dashboard create-self-signed-cert
#创建登录用户名和密码,执行命令如下:
ceph dashboard ac-user-create admin -i /etc/ceph/dashboard_passwd.txt administrator
#注意:-i用于指定密码文件,密码写在文件中,administrator为关键词,不用动注意:如果安装报错了,记得把上面的epel.repo的源还原回来就可以啦
通过浏览器访问ceph,地址如下:https://192.168.72.129:8443,如图:

注:因为mgr部署在了192.168.72.129上面因此通过此IP访问,如果三台机器都部署了mgr,那就要通过ceph -s 来查看哪个mgr为活动状态,使用此活动状态的mgr地址访问
如果dashboard中显示告警信息如图:
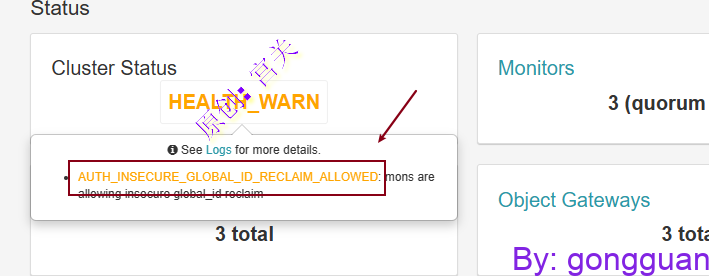
大致意思是Ceph 当前配置为允许客户端使用不安全的进程重新连接到监视器, auth_allow_insecure_global_id_reclaim设置此时为true,解决办法是将其改为false,在三个mon节点执行如下命令:
ceph config set mon auth_allow_insecure_global_id_reclaim false
16、dashboard启用RGW:
Ceph Dashboard默认安装好后,没有启用rgw,需要手工启用RGW,在主节点执行命令如下:
#注意:需要提前将上面生成的access_key和secret_key写入到文件中,然后通过-i指定,第14步中通过--system参数创建的用户才有权限开启RGW
cd /root/ceph
ceph dashboard set-rgw-api-access-key -i /etc/ceph/access_key
ceph dashboard set-rgw-api-secret-key -i /etc/ceph/secret_key
ceph dashboard set-rgw-api-ssl-verify False #禁用SSL设置完成后,点击主页面的 Object Gateways 即可看到内容,如图:

在Users下可以看到已经创建的用户
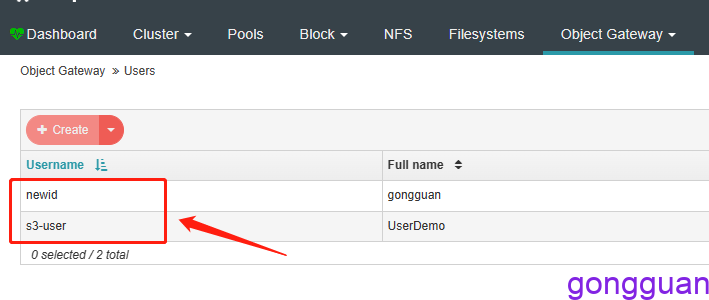
如果access_key和secret_key不记得了,可以在主节点执行如下命令:
radosgw-admin user info --uid=newid附加:
ceph.conf常用配置:
[global]
fsid = 9ec20e59-1033-4505-920d-113183167b31 #每个Ceph存储集群都有唯一的标识符(fsid)
mon allow pool delete = true #允许删除存储池
mon_max_pg_per_osd = 1000 #定义每个osd中的pg数量,默认为250
mon_initial members = ceph1,ceph2,ceph2 #集群节点,建议最少运行三个ceph监视器在生产存储集群,以确保高可用性
mon_host = 192.168.72.128,192.168.72.129,192.168.72.130#主机名并非主机IP
auth_cluster_required = cephx #如果启用了,集群守护进程(如ceph-mon、ceph-mds等)间必须相互认证。可用选项有 cephx 或 none 。默认是cephx启用。
auth_service_required = cephx #如果启用,客户端要访问 Ceph 服务的话,集群守护进程会要求它和集群认证。可用选项为 cephx 或 none 。类型:String是否必需:No默认值:cephx.
auth_client_required = cephx #如果启用,客户端会要求 Ceph 集群和它认证。可用选项为 cephx 或 none 。 默认就是cephx。
public_network = 192.168.1.0/24 #设置在[global]。可以指定以逗号分隔的子网。这是分配集群的外网网段,即对外数据交流的网段。
osd journal size = 1024 #缺省值为0。你应该使用这个参数来设置日志大小。日志大小应该至少是预期磁盘速度和filestore最大同步时间间隔的两倍。如果使用了SSD日志,最好创建大于10GB的日志,并调大filestore的最小、最大同步时间间隔。
osd pool default size = 5 #osd的默认副本数,不设置默认是3份。
osd pool default min size = 1 #缺省值是0.这是处于degraded状态的副本数目,它应该小于osd pool default size的值,为存储池中的object设置最小副本数目来确认写操作。即使集群处于degraded状态。如果最小值不匹配,Ceph将不会确认写操作给客户端。
osd crush chooseleaf type = 1 #CRUSH规则用到chooseleaf时的bucket的类型,默认值就是1.ceph集群管理:
(1) 启动停止所有守护进程
# systemctl restart/stop/start ceph.target
(2) 按类型启动守护进程
# systemctl restart ceph-osd@id
# systemctl restart ceph-mon.target
# systemctl restart ceph-mds.target
# systemctl restart ceph-mgr.targetceph集群管理常用命令:
ceph -v #查看ceph的版本
ceph -s #查看集群的状态
ceph -w #监控集群的实时更改
ceph osd pool ls # 查看存储池
ceph osd lspools #打印存储池列表
ceph osd tree #查看osd目录树
ceph osd df #查看osd的使用信息
ceph osd stat #查看osd状态
ceph osd find osd.0 #查看osd.0节点ip和主机名
ceph osd pool delete poolname poolname --yes-i-really-really-mean-it #删除存储池
ceph osd pool ls detail #查看池的的详细信息
ceph osd pool create temp-pool 128 #创建一个副本存储池,pg数量为128
ceph osd pool get temp-pool pg_num #查看temp-pool池的pg数量
ceph osd pool get temp-pool pgp_num #查看temp-pool池的pgp数量,pgp一般是与pg相等
ceph osd pool set temp-pool pg_num 128 #查看temp-pool池中的pg数量
ceph osd pool get temp-pool size #查看存储池副本数,默认为3
ceph osd pool set temp-pool size 4 #设置存储池副本数为4
ceph osd pool set temp-pool min_size 2 #设置存储池能接受写操作的最小副本为2
ceph osd pool stats #查看存储池的IO情况
ceph osd pool rename old-name new-name #存储池重命名
ceph osd pool get temp-pool nodelete #查看池temp-pool的nodelete机制,默认为false,不可删除
ceph osd pool set temp-pool nodelete true #设置temp-pool的nodelete机制为true,表示可删除
ceph osd force-create-pg 9.1d --yes-i-really-mean-it #强制创建unkown pg 9.1d就是上条命令获取
ceph osd dump #osd的映射信息
ceph osd down 0 #down掉osd.0节点
ceph osd rm 0 #集群删除一个osd硬盘
ceph osd crush remove osd.4 #删除标记
ceph osd getmaxosd #查看最大osd个数
ceph osd setmaxosd 10 #设置osd的个数
ceph osd out osd.3 #把一个osd节点逐出集群
ceph osd in osd.3 #把逐出的osd加入集群
ceph osd pause #暂停osd(暂停后整个集群不再接收数据)
ceph osd unpause #再次开启osd(开启后再次接收数据)
ceph osd df #查看osd的使用信息
ceph mon stat #查看mon状态
ceph mds stat #查看MDS 状态
ceph pg dump_stuck inactive #查看unkown状态的pg
ceph pg stat #查看pg状态的pg_stat的值
ceph pg dump #查看pg组的映射信息
ceph pg map 0.3f #查看一个pg的map
ceph pg 0.26 query #查看pg详细信息
ceph pg dump --format plain #显示一个集群中的所有的pg统计
rados lspools #查看ceph集群中有多少个pool
rados df #查看存储池使用情况: 每个pool容量及利用情况
rados create testobject -p temp-pool #temp-pool中创建一个对象testobject
rados rm test-object-1 -p temp-pool #删除存储池中的对象test-object
rados -p temp-pool ls #查看存储池temp-pool的对象附加:
1、在删除存储池的时候提示错误如下:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool原因:mon不允许删除存储池
解决方法:在/etc/ceph/ceph.conf中添加,如图:
mon allow pool delete = true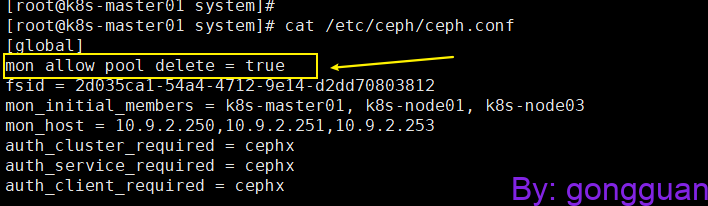
2、在设置存储池的pg数量时候,出现如下错误:
Error ERANGE: pool id 6 pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)或者too many PGs per OSD (256 > max 250)
原因:安装ceph后,默认的存储池中已经有很多pg,当设置新的存储池中的pg_num为128时,加上原有的,一个osd中pg总数超过了250,三个osd总数超过了750,因此告警
解决方案:编辑三台机器的配置文件/etc/ceph/ceph.conf,添加参数:
mon_max_pg_per_osd = 1000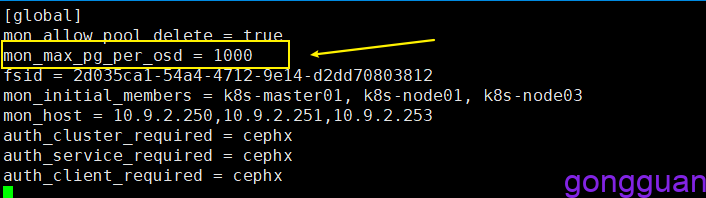
配置完成后,重启三台机器的mgr进程(ceph 12.2版本以前是重启mon)
3、删除存储池
删除存储池意味着数据的丢失,ceph为了防止意外删除存储池,实施了两个机制,第一个机制是nodelete,默认值为false,表示允许删除,如果要不允许删除需要将其改为true,第二个机制为集群范围的配置参数mon allow pool delete,默认值为false,表示不能删除,如果要删除需要在ceph.conf中改为true(上面的第1步中的配置就是改为了true)
查看存储池temp-pool的nodelete配置,默认情况为false,如图:

通过set命令设置nodelete为true,然后再次查看,如图:

注:需要将nodelete和mon allow pool delete都改为true后才可以顺利将存储池删除
4、存储池配额
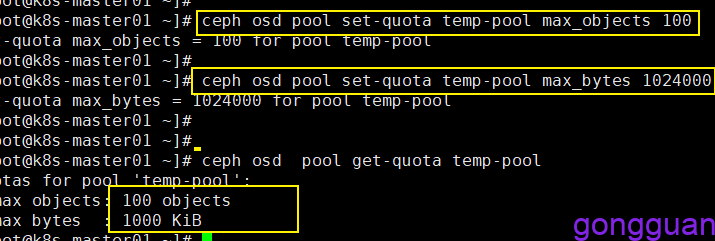
Ceph支持为存储池设置可存储对象的最大数量(max_objects)和可占用的最大空间(max_bytes),默认情况无限制
查看存储池temp-pool的配额,如图:

通过set命令设置max_objects和max_bytes,再次查看,如图:
5、配置存储池参数
存储池的诸多配置属性保存于配置参数中,获取配置:ceph osd pool get <pool-name> <key>;设定配置:ceph osd pool set <pool-name> <key> <value>
例如:
ceph osd pool get temp-pool size #获取存储池副本数
ceph osd pool set temp-pool size 5 #设置存储池副本数为5
ceph osd pool get temp-pool min_size #获取存储池最小副本数
ceph osd pool set temp-pool min_size 5 #设置存储池最小副本数
ceph osd pool get temp-pool pg_num #获取存储池的pg数
ceph osd pool set temp-pool pg_num 128 #设置存储池的pg数
ceph osd pool get temp-pool pgp_num6、存储池快照
ceph osd pool mksnap temp-pool temp-pool-snap #创建存储池快照
rados -p temp-pool mksnap temp-pool-snap #创建存储池快照与上面等价
rados -p temp-pool lssnap #查看存储池快照
ceph osd pool rmsnap temp-pool temp-pool-snap #删除存储池快照
rados -p temp-pool rmsnap temp-pool-snap #删除存储池快照与上面等价
rados -p temp-pool rollback temp-pool temp-pool-snap #回滚存储池到快照temp-pool-snap状态7、集群维护(关闭与启动)
重启之前,要提前设置 ceph 集群不要将 OSD 标记为 out,以及将backfill和recovery设置为no,避免 node 节点关闭服务后osd被踢出 ceph 集群外,以及存储池进行修复数据,等待节点维护完成后,再将所有标记取消设置,维护之前要先保证集群处于 “健康” 状态
关闭:
1、执行命令设置OSD标志,如下:
ceph osd set noout
ceph osd set norecover
ceph osd set nobackfill执行完毕后可以看到集群已告警,如图:
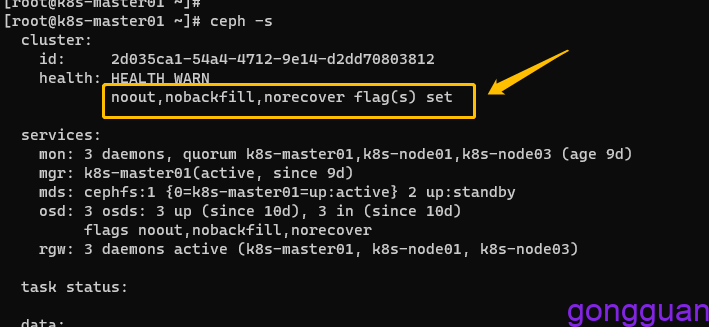
2、关闭相关组件:
- 如果使用了 RGW,关闭 RGW
- 关闭 cephfs 元数据服务
- 关闭 ceph OSD
- 关闭 ceph mgr
- 关闭 ceph mon
启动:
- 启动 ceph mon
- 启动 ceph mgr
- 启动 ceph osd
- 启动 cephfs
- 启动RGW
- 将之前设置的标志取消 ceph osd unset noout/norecover/nobackfill


