通过容器方式部署elk集群
简介:
ELK 是三个开源项目的首字母缩写: Elasticsearch、Logstash 和 Kibana
- Elasticsearch 是一个搜索和分析引擎
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,将数据发送到Elasticsearch等存储库中
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化
本例子中添加了消息中间件kafka,用来处理消息
早期架构中,日志收集以Logstash为主,Logstash负责收集和分析,但是它对内存、cpu、IO资源消耗很高,因此最新架构可通过filebeat进行收集,然后输出到kafka,在通过Logstash简单处理,输出到es中
架构:
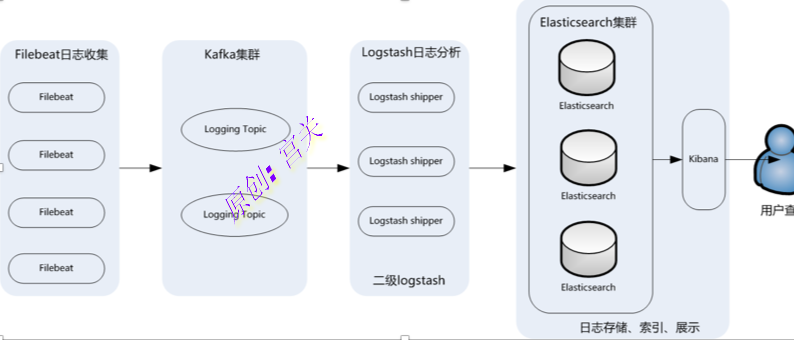
注意:如果不使用kafka也是可以的,架构为:filebeat收集数据后发送给logstash,logstash处理后直接发送给elasticsearch,最后通过Kibana展示出来
环境:
| centos7 | 192.168.120.129 | elk1 |
| centos7 | 192.168.120.130 | elk2 |
| centos7 | 192.168.120.131 | elk3 |
内存建议至少4G以上
一、安装docker:
可参考文章https://blog.ywdevops.cn/index.php/2020/04/19/centos/
二、安装elasticsearch:
1、创建存放yml文件的目录:
mkdir /data/elasticsearch2、创建docker-compose.yml文件:
cd /data/elasticsearch
touch docker-compose.yml3、docker-compose.yml的内容如下:
version: '3'
services:
elasticsearch: # 服务名称
image: registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch:8.15.2 # 使用的镜像
container_name: elasticsearch # 容器名称
restart: always # 失败自动重启策略
environment:
- node.name=elk3 # 节点名称,集群模式下每个节点名称唯一
- network.publish_host=192.168.120.131 # 用于集群内各机器间通信,对外使用,其他机器访问本机器的es服务,一般为本机宿主机IP
- network.host=0.0.0.0 # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,即本机
- discovery.seed_hosts=192.168.120.129,192.168.120.130,192.168.120.131 # es7.0之后新增的写法,写入候选主节点的设备地址,在开启服务后,如果master挂了,哪些可以被投票选为主节点
- cluster.initial_master_nodes=192.168.120.129,192.168.120.130,192.168.120.131 # es7.0之后新增的配置,初始化一个新的集群时需要此配置来选举master
- cluster.name=es-cluster # 集群名称,相同名称为一个集群, 三个es节点须一致
# - http.cors.enabled=true # 是否支持跨域,是:true // 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域
# - http.cors.allow-origin="*" # 表示支持所有域名 // 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域
- bootstrap.memory_lock=true # 内存交换的选项,官网建议为true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # 设置内存,如内存不足,可以尝试调低点
ulimits: # 栈内存的上限
memlock:
soft: -1 # 不限制
hard: -1 # 不限制
volumes:
- /data/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml # 将容器中es的配置文件映射到本地,本地必须提前先有该文件,设置跨域, 否则head插件无法连接该节点
- esdata:/usr/share/elasticsearch/data # 存放数据的文件, 注意:这里的esdata为 顶级volumes下的一项。
ports:
- 9200:9200 # http端口,可以直接浏览器访问
- 9300:9300 # es集群之间相互访问的端口,jar之间就是通过此端口进行tcp协议通信,遵循tcp协议。
volumes:
esdata:
driver: local # 会生成一个对应的目录和文件,如何查看,下面有说明。另外两台机器也按照这个文件配置,但network.publish_host和node.name需要修改
4、创建文件elasticsearch.yml:
#注意,三台机器都要创建
cd /data/elasticsearch
touch elasticsearch.yml
#也可以先随意启动一台elastic,然后通过docker cp /usr/share/elasticsearch/config/elasticsearch.yml拷贝出来即可5、设置内存:
#直接修改配置文件, 进入sysctl.conf文件添加一行(解决容器内存权限过小问题)
vi /etc/sysctl.conf
vm.max_map_count=262144 # 添加此行
sysctl -p #保存后执行此命令立即生效6、三台机器依次执行如下启动命令:
cd /data/elasticsearch
docker-compose up -d7、修改elasticsearch.yml文件,文件内容为:
network.host: 0.0.0.0
http.cors.enabled: true #是否支持跨域
http.cors.allow-origin: "*" #表示支持所有域名8、重启elasticsearch:
docker restart elasticsearch9、通过浏览器访问任意节点,显示如下表示集群成功,如图:
http://192.168.120.130:9200/_cluster/health?pretty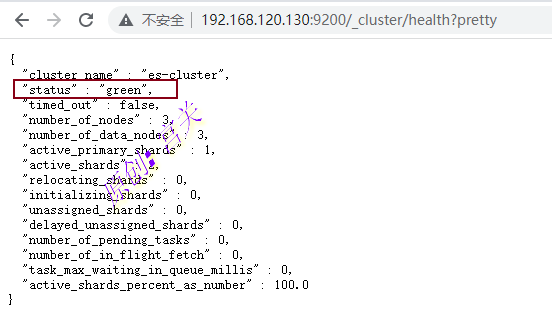
至此:elasticsearch集群部署完成
elasticsearch常用命令如下:
curl -X PUT "localhost:9200/index1?pretty" #创建索引index1
curl -X DELETE "localhost:9200/index1?pretty" #删除索引index1
curl -X GET "localhost:9200/_cat/indices?v" #查询所有索引
curl -X GET http://localhost:9200/_cat/nodes?v #获取集群节点列表
curl -X GET "localhost:9200/_cluster/health?pretty" #查看集群状态
curl -X GET http://localhost:9200/index_name/_settings?pretty #查看索引的副本数以及分片数(number_of_shards:分片数,number_of_replicas: 副本数)
curl -X PUT http://localhost:9200/index_name/_settings -H 'content-Type:application/json' -d '{"number_of_replicas":0}' #修改索引的副本数注意:elasticsearch部署后会自动创建网络名elasticsearch_default,可通过docker network ls查看
单节点可直接通过命令启动即可,也可根据其他需要定义挂载,如下:
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -v /data/elk/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -e "discovery.type=single-node" registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch:8.15.2单节点部署elasticsearch,运行一段时间后会发现状态变为yellow,索引副本数为: unassigned_shards” : 2,单节点的默认副本数为1,此时可以执行命令修改curl -X PUT “192.168.10.36:9200/_settings” -H ‘Content-Type: application/json’ -d'{“number_of_replicas”:0}’,再次查看已经变为green
三、部署elasticsearch-head来监控elasticsearch
#注:安装在一个节点就可以
docker pull mobz/elasticsearch-head:5
或
docker pull registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch-head:5
#运行
docker run -d -p 9100:9100 --name elasticsearch-head registry.cn-hangzhou.aliyuncs.com/workimage/elasticsearch-head:5通过安装节点的ipd地址和端口进行访问,如图:
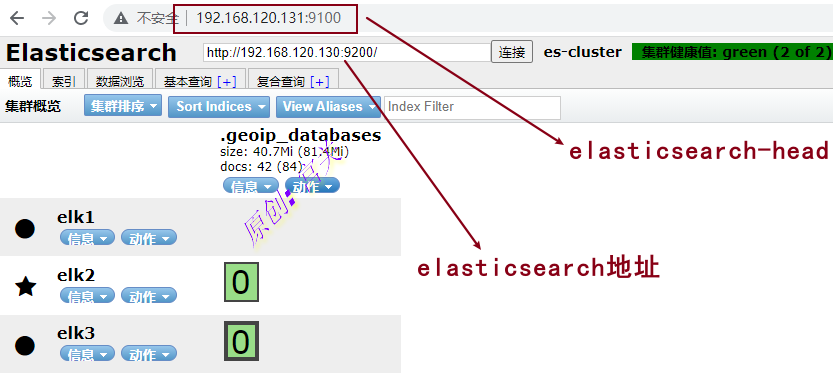
注意:如果elasticsearch-head无法连接elasticsearch,是因为elasticsearch的默认端口是9200 elasticsearch-head的端口是9100,会涉及到跨域问题所有无法直接连接,解决办法:
编辑elasticsearch.yaml配置文件,添加内容如下:
http.cors.enabled: true
http.cors.allow-origin: "*"添加完成后重启elasticsearch即可
四、部署kibana:
注:只需要部署一台即可
1、 创建kibana挂载目录:
mkdir /data/kibana/config2、创建kibana.yml文件:
cd /data/kibana/config
touch kibana.yml文件内容如下:
#访问kibana的地址
server.publicBaseUrl: "http://192.168.120.129:5601"
#Kibana的映射端口
server.port: 5601
#网关地址
server.host: "0.0.0.0"
#Kibana实例对外展示的名称
server.name: "kibana"
#Elasticsearch的集群地址,也就是说所有的集群IP
elasticsearch.hosts: ["http://192.168.120.129:9200","http://192.168.120.130:9200","http://192.168.120.131:9200"]
#设置页面语言,中文使用zh-CN,英文使用en
i18n.locale: "zh-CN"
xpack.monitoring.ui.container.elasticsearch.enabled: true启动kibana:
docker run -d --name kibana --network=elasticsearch_default -p 5601:5601 -v /data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml -v /etc/localtime:/etc/localtime --privileged=true registry.cn-hangzhou.aliyuncs.com/workimage/kibana:7.15.2
#指定网络名elasticsearch_default,与elasticsearch运行再同一个网络上
五、部署kafka:
注:三台机器都要部署,要提前安装好jdk环境,否则无法启动
1、配置zookeeper:
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序
tar -xf kafka_2.12-3.0.0.tgz -C /data //解压到指定目录
cd /data
ln -s kafka_2.12-3.0.0 kafka //创建一个软连接编辑文件zookeeper.properties:
vim /data/kafka/config/zookeeper.properties
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
clientPort=2181
maxClientCnxns=0
admin.enableServer=false
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.120.129:2888:3888
server.2=192.168.120.130:2888:3888
server.3=192.168.120.131:2888:3888
#注意:server的值要和后面的id对应
参数含义:
dataDir:zk数据存放目录
dataLogDir:zk日志存放目录
clientPort: 客户端连接zk服务端口
maxClientCnxns:设置0表示不限制并发连接数
tickTime:zk服务器之间或客户端与服务器之间心跳间隔
initLimit:允许follower(相对于leader而言的“客户端”)连接并同步到leader的初始化连接时间,它是以tickTime的倍数来表示的
syncLimit:Leader与Follower之间发送消息时,请求和应答时间长度,如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃
server:2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。创建数据目录和日志目录:
mkdir -p /data/zookeeper/{data,log}2、配置kafka:
编辑文件server.properties:
vim /data/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://192.168.120.129:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.120.129:2181,192.168.120.130:2181,192.168.120.131:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
auto.create.topics.enable=true
delete.topics.enable=true
参数含义:
broker.id:每个server需要单独配置broker id,如果不配置系统会自动配置,例如129机器配置为1,那么130可配置为2,131可配置为3
listeners:监听地址,每台机器配置自己的IP地址
num.network.threads:接收和发送网络信息的线程数
num.io.threads:服务器用于处理请求的线程数,其中可能包括磁盘I/O
socket.send.buffer.bytes:套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes: 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes: 套接字服务器将接受的请求的最大大小(防止OOM)
log.dirs: 日志文件目录
num.partitions: partition数量
num.recovery.threads.per.data.dir: 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1
offsets.topic.replication.factor: 偏移量话题的复制因子,为了保证有效的复制
log.retention.hours: 日志文件删除之前保留的时间(单位小时),默认168
log.segment.bytes: 单个日志文件的大小,默认1073741824
log.retention.check.interval.ms: 检查日志段以查看是否可以根据保留策略删除它们的时间间隔
zookeeper.connect: ZK主机地址,如果zookeeper是集群则以逗号隔开
zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间
auto.create.topics.enable:当有producer向一个不存在的topic中写入消息时,是否自动创建该topic
delete.topics.enable:kafka提供了删除topic的功能,但默认并不会直接将topic数据物理删除。如果要从物理上删除(删除topic后,数据文件也一并删除),则需要将此项设置为true注意:listeners的9092端口前面一定要写上本机IP,否则kafka是接收不到数据的
创建kafka日志目录:
mkdir -p /data/kafka/logs三台机器分别创建myid文件:
echo 1 > /data/zookeeper/data/myid #192.168.120.129
echo 2 > /data/zookeeper/data/myid #192.168.120.130
echo 3 > /data/zookeeper/data/myid #192.168.120.1313、启动验证集群:
#首先启动zookeeper,三台机器都执行
cd /data/kafka
nohup bin/zookeeper-sever-start.sh config/zookeeper.properties &
#启动后可以查看到端口2181如下:
[root@elk1 kafka]# netstat -lntup |grep 2181
tcp6 0 0 :::2181 :::* LISTEN 20653/java 注意:zookeeper是有leader节点和follow节点,哪个节点监听了2888端口那么此节点即为leader节点
#启动kafka,三台机器都执行
cd /data/kafka
nohup bin/kafka-server-start.sh config/server.properties &
#启动后可以看到监听端口9092在运行:
[root@elk3 kafka]# netstat -lntup | grep 9092
tcp6 0 0 192.168.120.131:9092 :::* LISTEN 22209/java 验证:
在任意节点作为生产者生产消息:
#创建testtopic,在任意一个节点执行命令如下:
cd /data/kafka/bin
./kafka-console-producer.sh --bootstrap-server 192.168.120.129:9092 --topic testtopic
在任意其他节点上,执行消费命令:
cd /data/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.120.130:9092 --topic testtopic --from-beginning
#注意:上图中消费地址用的是192.168.120.130,因为kafka是一个集群,因此用哪个地址都可以,也可以用192.168.120.129/131
#--from-beginning:表示从最开始的时候开始消费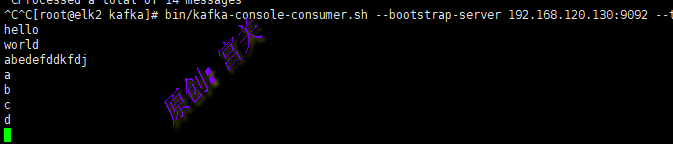
从上图可以看出,已经可以实现正常的生产和消费
常用命令:
#创建一个topic:
./kafka-topics.sh --create --bootstrap-server 192.168.120.129:9092 --replication-factor 2 --partitions 3 --topic mytopic
#--replication-factor:指定创建这个topic的副本数
#--partitions:指定该topic的分区数
#--topic:指定topic的名称
#列出现有topic
./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --list
#查看topic详细信息
./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --describe --topic mystopic
#删除topic
./kafka-topics.sh --bootstrap-server 192.168.120.131:9092 --delete --topic mystopic六、部署logstash:
1、下载镜像:
docker pull registry.cn-hangzhou.aliyuncs.com/workimage/logstash:7.15.22、创建配置文件:
mkdir -p /data/logstash/conf.d
touch /data/logstash/logstash.yml3、logstash.yml文件内容如下:
path.config: /usr/share/logstash/conf.d/*.conf
path.logs: /var/log/logstash
#注意:这个文件是要挂载到内部的,因此路径要是内部的路径才对4、在conf.d下创建配置文件:
#注意:如果没有此配置文件,logstash容器起不来
vim nginx_access_log.conf
#内容如下:
input {
kafka{
bootstrap_servers => "192.168.120.129:9092,192.168.120.130:9092,192.168.120.131:9092"
group_id => "nginx_access_log"
topics => ["nginx_access_log"]
codec => json { charset => "UTF-8" }
type => "nginx_access"
}
}
output{
elasticsearch {
hosts => ["192.168.120.129:9200","192.168.120.130:9200","192.168.120.131:9200"]
index => "nginx_access_log-%{+YYYY.MM.dd}"
}
stdout { codec => json }
}
参数说明:
#group_id: 指定消费组,如果不指定,默认为logstash
#topic:消费主题,和filebeat中的定义的要一一对应
#codec: 转换为json格式,并指定编码
#type:定义类型,如果有多个kafka,可以区分
#hosts: 指定elasticsearch地址
#index: 设置索引,此索引设置后kibana中可以看到
#stout: 输入到elasticsearch中的类型为json
#input: 输入内容
#output:输出内容
#filter: 过滤插件,再次没有使用5、创建容器:
docker run -d --net=elasticsearch_default \
-p 5044:5044 -p 5045:5045 --name logstash \
-v /data/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /data/logstash/conf.d/:/usr/share/logstash/conf.d/ \
registry.cn-hangzhou.aliyuncs.com/workimage/logstash:7.15.2注意:严格意义上说logstash并不存在集群,但是可以通过每台机器上都部署一台,来实现采集本节点的日志
七、部署filebeat:
filebeat主要功能用来采集日志,然后发送到kafka
1、拉取镜像:
#要采集哪个机器的日志,就要在这机器上运行filebeat
docker pull registry.cn-hangzhou.aliyuncs.com/workimage/filebeat:7.15.22、创建日志文件夹路径:
mkdir -p /data/filebeat/log3、创建filebeat.yml文件,内容如下:
vim /data/filebeat/filebeat.yml
#filebeat自身日志配置
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 0644
# 日志输入配置(可配置多个)
filebeat.inputs:
- type: log #定义采集nginx的access日志
enabled: true
paths:
- /var/log/nginx/access.log
tags: ["nginx-access"]
fields:
kafka_topic: nginx_access_log #自定义字段,用来区分的
multiline:
pattern: ^[[:alnum:]] #^[[:alnum:]] 匹配任意数字字母开头
negate: true
match: after
multiline.max_lines: 5000
processors:
- drop_fields:
fields: ["beat","input","source","offset"]
#output.file: #测试是否采集到日志,如果采集到输出到file.txt中
# path: "/tmp/file.txt"
# filename "filebeat"
#日志输出配置,如果配置了output.file就不能配置output,kafka,同一时间只能有一个output
output.kafka:
enabled: true
hosts: ["192.168.120.129:9092","192.168.120.130:9092","192.168.120.131:9092"]
topic: '%{[fields.kafka_topic]}'
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
#multiline:此参数功能是可以将日志全部发送到kafka而不发生截断,注意其中的pattern后面的正则表达式,要根据实际需要编写,否则可能出现无法匹配到合适的日志文件,导致无法采集,进而无法生成索引注意:上图配置文件filebeat.yml是要挂载到容器里,因此采集日志的路径也是针对容器里的路径,而我们需要采集的是外面宿主机的日志路径,因此需要将外面的日志路径挂载进入,multiline的pattern后面的正则,要根据实际情况编写,否则采集不到日志,切记!!!
4、执行命令启动filebeat:
docker run -d --name filebeat \
-v /data/filebeat/log:/var/log/filebeat \
-v /data/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \
-v /var/log/nginx:/var/log/nginx \
-v /etc/localtime:/etc/localtime \
registry.cn-hangzhou.aliyuncs.com/workimage/filebeat:7.15.2注意:/data/filebeat目录以及子目录要设置755权限或者更高才可以
八、验证:
1、首先登录elasticsearch_head,可以看到默认的几个索引,如图:
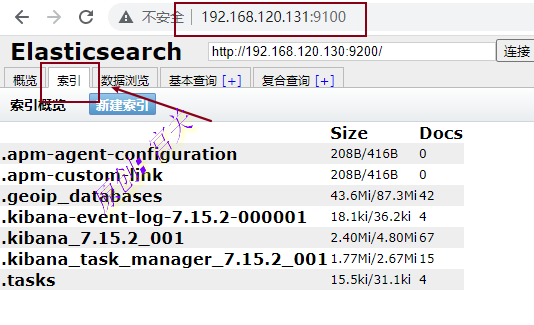
刷新nginx页面后,可以看到新增了索引,如图:
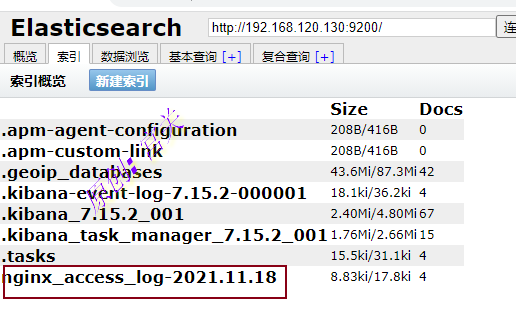
从上图中可以看出,索引名称就是logstash的配置文件中定义的index的值
在kafka的消费端执行命令同样可以看出数据,如图:
./kafka-console-consumer.sh --bootstrap-server 192.168.120.129:9092 --topic nginx_access_log --from-beginning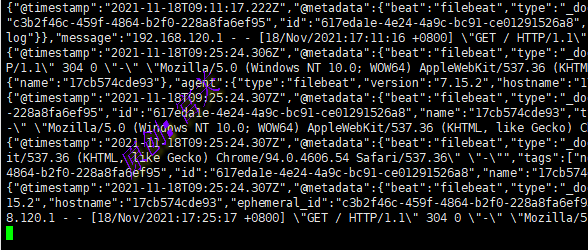
验证结论:
filebeat采集到了nginx的access.log日志,并发送到kafka中,logstash在从kafka中拿到数据,然后发送给es,最终储存在了es中,并自动创建了索引
九、kibana配置索引模式:
1、点击主页面的添加数据-日志-nginx日志,如图:
2、创建索引模式,如图:
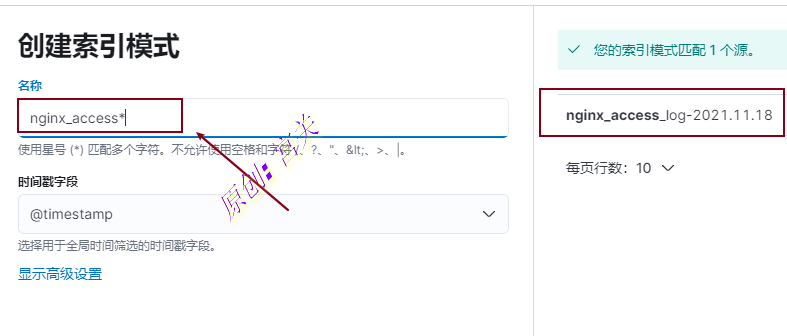
注意:输入的索引名称一定是存在的字段,也就是elasticsearch存在的索引才可以,此索引为logstash传递数据到es中的时候自动创建的
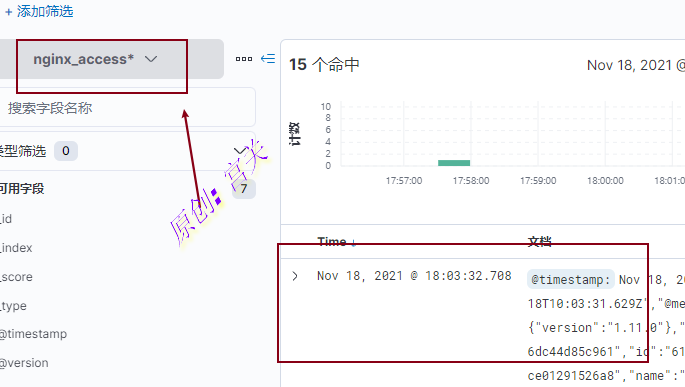
3、创建后点击Analytics下面的Discover即可看到日志,如图:
附加:
上面的例子只是采集单一日志,那么如果要采集同一台机器上的多个日志文件,此时应该怎么做呢?
1、首先编辑配置文件filebeat.yml,如下:
vim /data/filebeat/filebeat.yml文件内容如下:
#filebeat自身日志配置
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 0644
# 日志输入配置(可配置多个)
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log #采集access.log日志
tags: ["nginx-access"]
fields:
kafka_topic: nginx_access_log
- type: log
enabled: true
paths:
- /var/log/nginx/error.log #采集error.log日志
tags: ["nginx-error"]
fields:
kafka_topic: nginx_error_log
- type: log
enabled: true
paths:
- /var/log/java/*.log #采集Java日志下所有日志
tags: ["java-log"]
fields:
kafka_topic: java_log #自定义字段,用来区分的
#processors:
#- drop_fields:
# fields: ["beat","input","source","offset"]
#日志输出配置
output.kafka:
enabled: true
hosts: ["192.168.120.129:9092","192.168.120.130:9092","192.168.120.131:9092"]
topic: '%{[fields.kafka_topic]}'
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000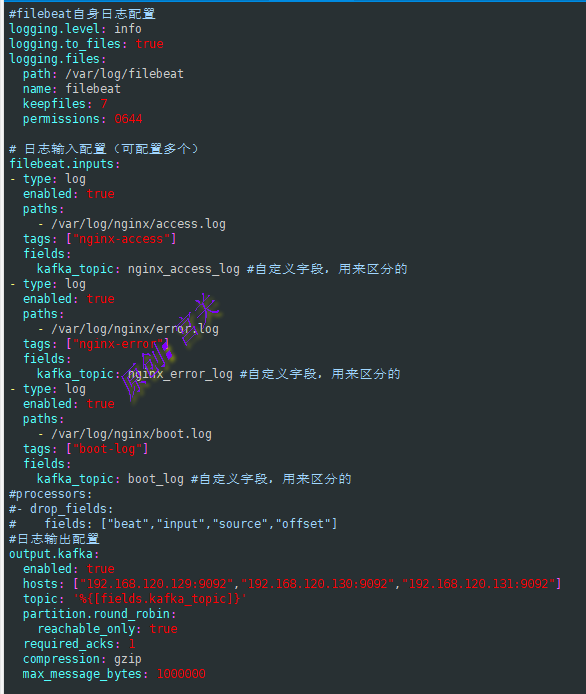
2、编辑logstash的配置文件logstash.conf,如下:
#注意:名字可自定义,不一定是logstash.conf
vim /data/logstash/conf.d/logstash.conf文件内容如下:
input {
kafka {
bootstrap_servers => "192.168.120.129:9092,192.168.120.130:9092,192.168.120.131:9092"
group_id => "nginx_access_log"
topics => ["nginx_access_log"]
codec => json { charset => "UTF-8" }
type => "nginx_access"
}
kafka {
bootstrap_servers => "192.168.120.129:9092,192.168.120.130:9092,192.168.120.131:9092"
group_id => "nginx_error_log"
topics => ["nginx_error_log"]
codec => json { charset => "UTF-8" }
type => "nginx_error"
}
kafka {
bootstrap_servers => "192.168.120.129:9092,192.168.120.130:9092,192.168.120.131:9092"
group_id => "boot_log"
topics => ["boot_log"]
codec => json { charset => "UTF-8" }
type => "boot"
}
}
output{
if [type] == "nginx_access" {
elasticsearch {
hosts => ["192.168.120.129:9200","192.168.120.130:9200","192.168.120.131:9200"]
index => "nginx_access_log-%{+YYYY.MM.dd}"
}}
if [type] == "nginx_error" {
elasticsearch {
hosts => ["192.168.120.129:9200","192.168.120.130:9200","192.168.120.131:9200"]
index => "nginx_error_log-%{+YYYY.MM.dd}"
}}
if [type] == "boot" {
elasticsearch {
hosts => ["192.168.120.129:9200","192.168.120.130:9200","192.168.120.131:9200"]
index => "boot_log-%{+YYYY.MM.dd}"
}}
stdout { codec => json }
} 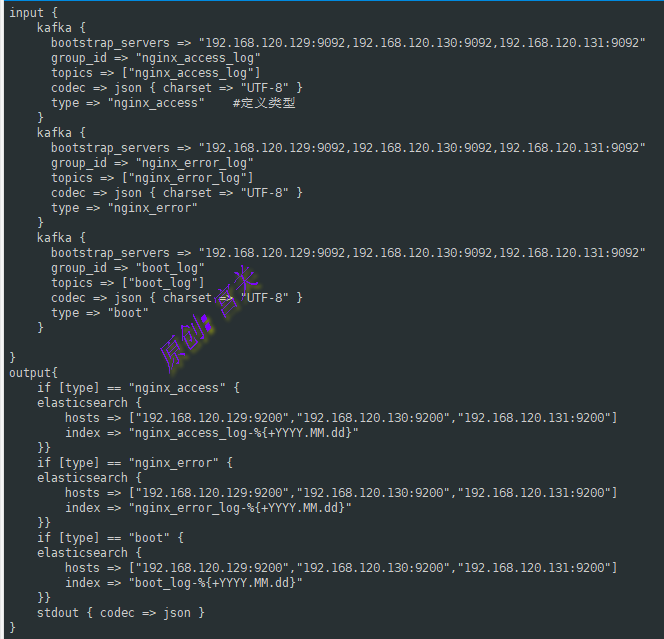
从上图可以看出,下面的output根据定义的type类型来输出到elasticsearch并创建索引
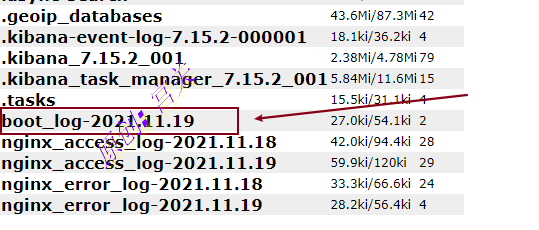
3、在elasticsearch-head中,可以看到索引已经创建,如图:
常见问题:
1、日志采集不到问题:
如果用容器跑filebeat,那么采集的路径是容器内的路径,如果采集本机的,一定要将路径挂载到容器内才可以采集到,否则会无法采集到,如果是本地跑filebeat不会有这种问题
2、日志显示不全问题:
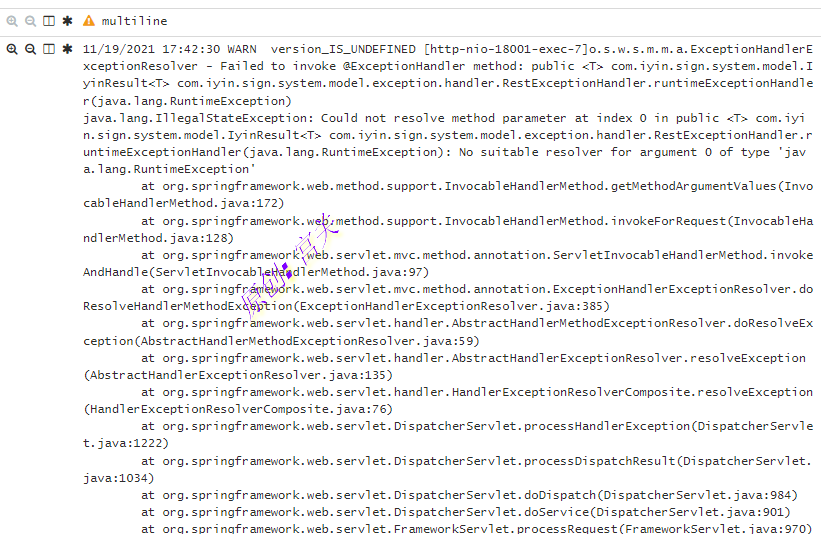
默认情况下kibana中的message显示的内容很少,无法满足正常的日志查看,如图:

通过kafka查看,是filebeat采集日志后发生了截断,导致数据不全,此时需要在filebeat中进行设置,参数内容为:
multiline:
pattern: '^[0-9]{4}-[0-9]{2}.*'
negate: true
match: after
multiline.max_lines: 5000
# multiline.max_lines: 单一多行匹配聚合的最大行数,超过定义行数后的行会被丢弃,默认500具体的multiline配置可参考上方的filebeat.yml配置,配置完后重启filebeat,再次在kibana中查看日志,可以看到显示如下:
ELK数据清理脚本,可按月份清理索引以及数据,防止磁盘空间占用过大,如下:
#!/bin/bash
" '
@function: 清理elk的数据
@author: gongguan
@time: 20230330
@说明: 可修改下面的2023和01来确定删除的月份和年份
'
result=$(curl 'localhost:9200/_cat/indices?v' | awk '{print $3}' | sed -n "/^prd/p" | sed -n "/2023.01/p")
for i in ${result}
do
curl -XDELETE http://localhost:9200/${i}
done常见问题:
1、磁盘空间不够导致无法分片,此时可以设置elasticsearch能使用的最大比例磁盘空间,命令如下:
curl -X PUT http://localhost:9200/_cluster/settings -H 'content-Type:application/json' -d '{"transient": {"cluster.routing.allocation.disk.watermark.low": "90%"}}'2、分片未分配,导致集群状态为yellow,通过分析命令查看报错信息如下:
分析命令如下:
curl -X GET http://192.168.51.241:9200/_cluster/allocation/explain?pretty报错内容为:a copy of this shard is already allocated to this node,这个由于这个复制分片已经分配到此节点, 那么解决方案就是把复制分片(分片副本)设置为0(number_of_replicas: 0),执行命令如下:
curl -X PUT http://localhost:9200/index_name/_settings -H 'content-Type:application/json' -d '{"number_of_replicas":0}'修改完成后,集群状态即为Green
注意:单节点的elasticsearch,不需要分片副本,因此可将number_of_replicas设置为0


