k8s存储卷pv、pvc、StorageClass
Kubernetes支持类似的存储卷功能以实现短生命周期的容器应用数据的持久化,不过,其存储卷绑定于Pod对象而非容器级别,并可共享给内部的所有容器使用。
一、存储卷基础:
Pod本身有生命周期,其应用容器及生成的数据自身均无法独立于该生命周期之外持久存在,并且同一Pod中的容器可共享PID、Network、IPC和UTS名称空间,但Mount和USER名称空间却各自独立,因而跨容器的进程彼此间默认无法基于共享的存储空间交换文件或数据。因而,借助特定的存储机制甚至是独立于Pod生命周期的存储设备完成数据持久化
1、存储卷概述:
简单来说,存储卷是定义在Pod资源之上可被其内部的所有容器挂载的共享目录,该目录关联至宿主机或某外部的存储设备之上的存储空间,可由Pod内的多个容器同时挂载使用。Pod存储卷独立于容器自身的文件系统,因而也独立于容器的生命周期,它存储的数据可于容器重启或重建后继续使用,下图表示pod容器与存储卷之间关系,如图:
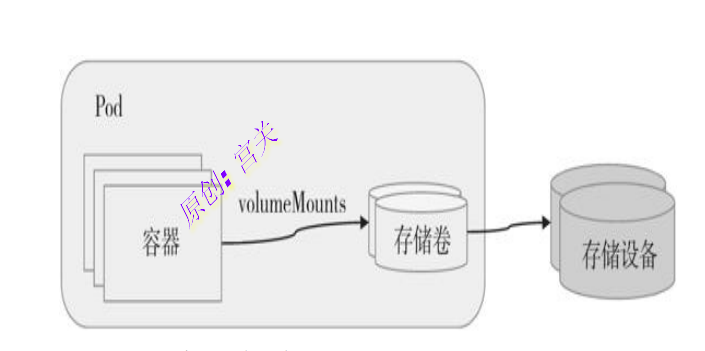
Kubernetes系统内置了多种类型的存储卷插件,因而能够直接支持多种类型存储系统(即存储服务方),例如CephFS、NFS、RBD、iscsi和vSphereVolume等。定义Pod资源时,用户可在其spec.volumes字段中嵌套配置选定的存储卷插件,并结合相应的存储服务来使用特定类型的存储卷,甚至使用CS或flexVolume存储卷插件来扩展支持更多的存储服务系统。
Kubernetes支持的存储卷可简单归为以下类别,它们也各自有着不少的实现插件:
(1):临时存储卷:emptyDir
(2):本地存储卷:hostPath和local
(3):网络存储卷,主要包括:
- 云存储——awsElasticBlockStore、gcePersistentDisk、azureDisk和azureFile。
- 网络文件系统——NFS、GlusterFS、CephFS和Cinder。
- 网络块设备——iscsi、FC、RBD和vSphereVolume
- 网络存储平台——Quobyte、PortworxVolume、StorageOS和
(4):特殊存储卷:Secret、ConfigMap、DownwardAPI和Projected。
(5):扩展支持第三方存储的存储接口(Out-of-Tree卷插件):CSI和FlexVolume。
2、配置Pod存储卷:
在Pod中定义使用存储卷的配置由两部分组成:一部分通过.spec.volumes字段定义在Pod之上的存储卷列表,它经由特定的存储卷插件并结合特定的存储系统的访问接口进行定义;另一部分是嵌套定义在容器的volumeMounts字段上的存储卷挂载列表,它只能挂载当前Pod对象中定义的存储卷。不过,定义了存储卷的Pod内的容器也可以选择不挂载任何存储卷。
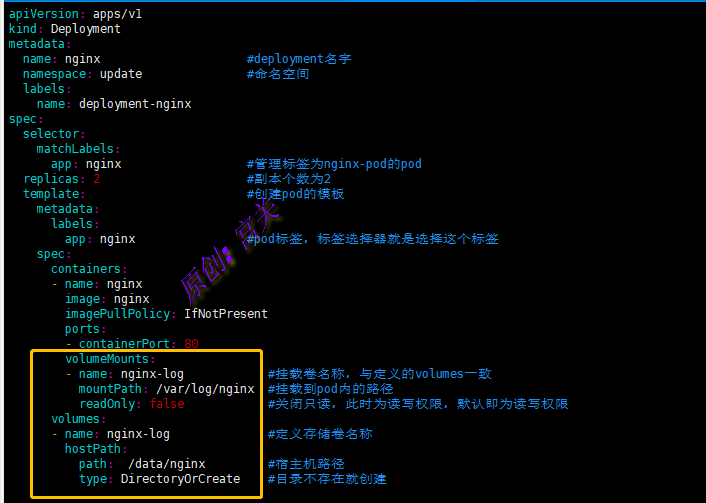
下图1中例子表示将宿主机的路径,挂载到Pod中nginx容器的日志路径,如图:
二、临时存储卷:
Kubernetes支持的存储卷类型中,emptyDir存储卷的生命周期与其所属的Pod对象相同,它无法脱离Pod对象的生命周期提供数据存储功能,因此通常仅用于数据缓存或临时存储。不过,基于emptyDir构建的gitRepo存储卷可以在Pod对象的生命周期起始时,从相应的Git仓库中克隆相应的数据文件到底层的emptyDir中,也就使得它具有了一定意义上的持久性
1、emptyDir存储卷:
emptyDir存储卷可以理解为Pod对象上的一个临时目录,类似于Docker上的“Docker挂载卷”,在Pod对象启动时即被创建,而在Pod对象被移除时一并被删除。因此,emptyDir存储卷只能用于某些特殊场景中,例如同一Pod内的多个容器间的文件共享,或作为容器数据的临时存储目录用于数据缓存系统等。
emptyDir存储卷可用字段主要有两个:
- medium:此目录所在的存储介质的类型,可用值为default或Memory,默认为default,表示使用节点的默认存储介质,也就是磁盘空间;Memory表示使用基于RAM的临时文件系统tmpfs,总体可用空间受限于内存,但性能非常好,通常用于为容器中的应用提供缓存存储。
- sizeLimit:当前存储卷的空间限额,默认值为nil,表示不限制;不过,在medium字段值为Memory时,建议务必定义此限额。
下面例子表示同一pod中的busybox容器共享tomcat容器的日志,如图:
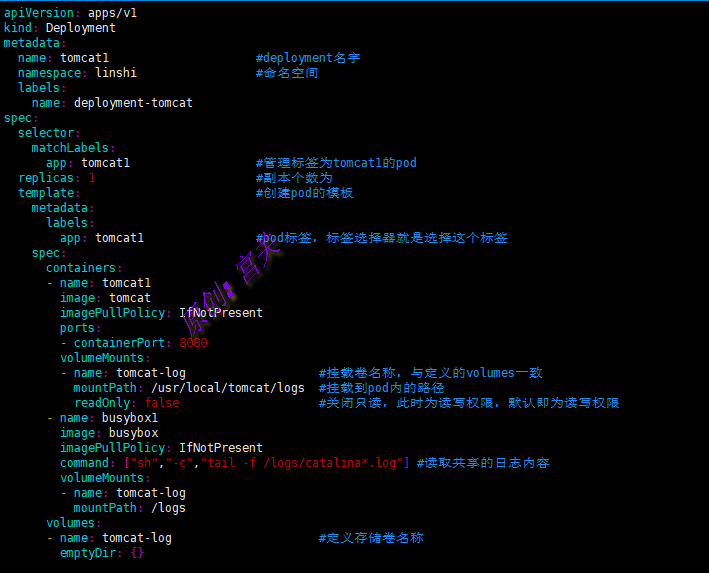
上图中使用emptyDir存储卷,通过此卷实现tomcat和busybox容器共享存储卷,emptyDir卷简单易用,但仅能用于临时存储。
emptyDir配合字段使用方法如下:
emptyDir: {}
medium: Memory
siteLimit: 64Mi #此参数可单独使用,但是如果配置了Memory建议一定要配置此参数三、hostPath存储卷:
hostPath存储卷插件是将工作节点上某文件系统的目录或文件关联到Pod上的一种存储卷类型,其数据具有同工作节点生命周期一样的持久性。hostPath存储卷使用的是工作节点本地的存储空间,所以仅适用于特定情况下的存储卷使用需求,例如将工作节点上的文件系统关联为Pod的存储卷,从而让容器访问节点文件系统上的数据,hostPath存储卷在运行有管理任务的系统级Pod资源,以及Pod资源需要访问节点上的文件时尤为有用。
配置hostPath存储卷的嵌套字段有两个:一个用于指定工作节点上的目录路径的必选字段path;另一个用于指定节点之上存储类型的type。hostPath支持使用的节点存储类型有如下几种:
- DirectoryOrCreate:指定的路径不存在时,自动将其创建为0755权限的空目录,属主和属组均为kubelet
- Directory:事先必须存在的目录路径
- FileOrCreate:指定的路径不存在时,自动将其创建为0644权限的空文件,属主和属组均为kubelet
- File:文件,必须存在的文件路径
- Socket:事先必须存在的Socket文件路径
- CharDevice:事先必须存在的字符设备文件路径
- BlockDevice: 事先必须存在的块设备文件路径
- “” :空字符串,默认配置,在关联hostPath存储卷之前不进行任何检查
这类Pod对象通常受控于DaemonSet类型的Pod控制器,它运行在集群中的每个工作节点上,负责收集工作节点上系统级的相关数据,因此使用hostPath存储卷也理所应当。然而,基于同一个模板创建Pod对象仍可能会因节点上文件的不同而存在着不同的行为,而且在节点上创建的文件或目录默认仅root用户可写,若期望容器内的进程拥有写权限,则需要将该容器运行于特权模式,不过这存在潜在的安全风险
四、网络存储卷:
Kubernetes内置了多种类型的网络存储卷插件,它们支持的存储服务包括传统的NAS或SAN设备(例如NFS、iscsi和FC等)、分布式存储(例如GlusterFS、CephFS和RBD等)、云存储(例如gcePersistentDisk、azureDisk、Cinder和awsElasticBlockStore等)、以及构建在各类存储系统之上的抽象管理层(例如flocker、portworxVolume和vSphereVolume等),这类服务通常都是独立运行的存储系统,因相应的存储卷可以支持超越节点生命周期的数据持久性
1、NFS存储卷:
NFS即网络文件系统(Network File System),它是一种分布式文件系统协议其功能旨在允许客户端主机可以像访问本地存储一样通过网络访问服务器端文件
Kubernetes的NFS存储卷用于关联某事先存在的NFS服务器上导出(共享)的存储空间到Pod对象中以供容器使用,该类型的存储卷在Pod对象终止后仅是被卸载而非被删除。而且,NFS是文件系统级共享服务,它支持同时存在的多路挂载请求,可由多个Pod对象同时关联使用。NFS存储卷时支持嵌套使用以下几个字段:
- server :NFS服务器的IP地址或主机名,必选字段
- path :NFS服务器导出(共享)的文件系统路径,必选字段
- readOnly :是否以只读方式挂载,默认为false
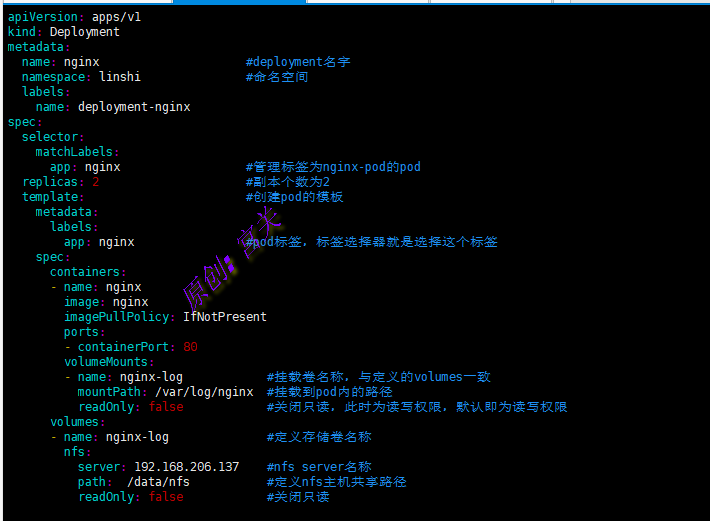
下面例子表示将nginx的日志,挂载到nfs共享路径/data/nfs下,如图:
pod创建完成后,在nfs服务器的/data/nfs路径下可以看到挂载的内容,如图:

nfs的共享配置文件表明允许pod所在的主机IP挂载,内容如下:

注意上图中的蓝色字体,共享给的IP地址为pod所在的宿主机地址,不是Pod地址,如果写pod地址不通
2、RBD存储卷
待搭建环境测试
3、CephFS存储卷
待搭建环境测试
4、GlusterFS存储卷
待搭建环境测试
五、持久存储卷:
PV(PersistentVolume)与PVC(PersistentVolumeClaim)是在用户与存储服务之间添加的一个中间层,管理员事先根据PV支持的存储卷插件及适配的存储方案(目标存储系统)细节定义好可以支撑存储卷的底层存储空间,而后由用户通过PVC声明要使用的存储特性来绑定符合条件的最佳PV定义存储卷,从而实现存储系统的使用与管理职能的解耦,大大简化了用户使用存储的方式。
PV和PVC的生命周期由Controller Manager中专用的PV控制器(PV Controller) 独立管理,这种机制的存储卷不再依附并受限于Pod对象的生命周期,从而实现了用户和集群管理员的职责相分离
1、PV与PVC基础:
PV是由集群管理员于全局级别配置的预挂载存储空间,它通过支持的存储卷插件及给定的配置参数关联至某个存储系统上可用数据存储的一段空间,这段存储空间可能是Ceph存储系统上的一个存储映像、一个文件系统(CephFS)或其子目录,也可能是NFS存储系统上的一个共享目录等,PV将存储系统之上的存储空间抽象为Kubernetes系统全局级别的API资源,由集群管理员负责管理和维护。
将PV提供的存储空间用于Pod对象的存储卷时,用户需要事先使用PVC在名称空间级别声明所需要的存储空间大小及访问模式并提交给Kubernetes API Server,接下来由PV控制器负责查找与之匹配的PV资源并完成绑定。随后,用户在Pod资源中使用persistentVolumeClaim类型的存储卷插件指明要使用的PVC对象的名称即可使用其绑定到的PV所指向的存储空间,如图:
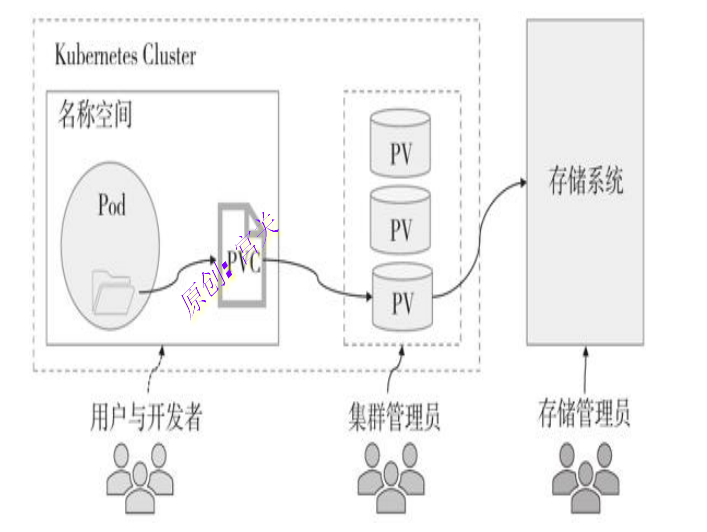
简单理解就是:存储系统通过CSI与k8s对接后,管理员创建PV,如果pod想使用pv空间,就要先定一个pvc来向pv申请空间,然后把pvc和pod绑定即可
PV和PVC是一对一的关系:一个PVC仅能绑定一个PV,而一个PV在某一时刻也仅可被一个PVC所绑定。为了能够让用户更精细地表达存储需求,PV资源对象的定义支持存储容量、存储类、卷模型和访问模式等属性维度的约束。相应地,PVC资源能够从访问模式、数据源、存储资源容量需求和限制、标签选择器、存储类名称、卷模型和卷名称等多个不同的维度向PV资源发起匹配请求并完成筛选。
注意:PV属于集群级别,PVC属于命名空间级别,PV目前没有Namespace隔离,不需要指定命名空间,在任意命名空间下创建的PV均可以在其他Namespace使用
下面例子中,使用NFS存储系统的PV资源,它将空间大小限制为5GB,并支持单路读写操作,如图:
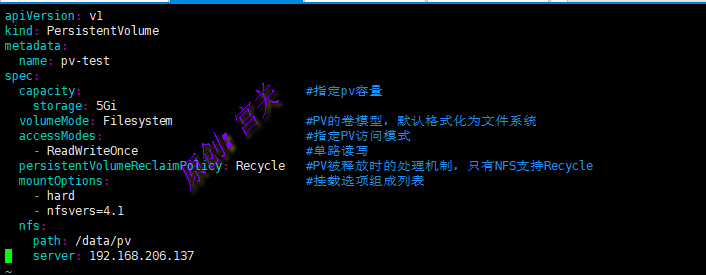
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-test
spec:
capacity: #指定pv容量
storage: 5Gi
volumeMode: Filesystem #PV的卷模型,默认格式化为文件系统
accessModes: #指定PV访问模式
- ReadWriteOnce #单路读写
persistentVolumeReclaimPolicy: Recycle #PV被释放时的处理机制,只有NFS支持Recycle
mountOptions: #挂载选项组成列表
- hard
- nfsvers=4.1
nfs:
path: /data/pv
server: 192.168.206.137
执行命令创建PV,若能够正确关联到指定的后端存储,该PV对象的状态将显示为Available,否则其状态为Pending,如图:

下面例子中,定义了一个PVC向pv申请资源,它仅定义了期望的存储空间范围、访问模式和卷模式以筛选集群上的PV资源,如图:

创建PVC后,此时控制平面会在集群中寻找一个符合条件的PV来与PVC进行绑定,绑定后状态将从Available变成Bound,如图:
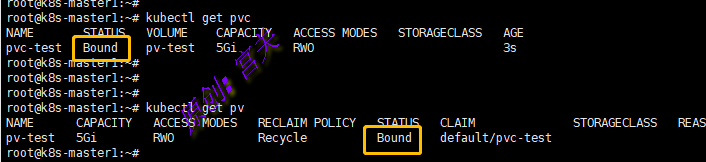
注意:PVC和PV进行绑定的前提条件是一些参数必须匹配,比如accessModes、storageClassName、volumeMode都需要相同,并且PVC的storage需要小于等于PV的storage配置,否侧绑定失败
下面例子表示在pod中使用pvc,如图:
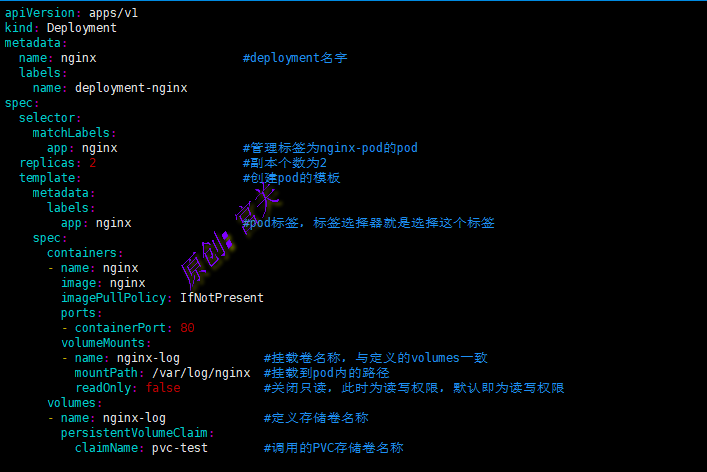
创建完pod后,可以看到,已经看到pv中的指定的存储路径已经挂载出来内容,如图:
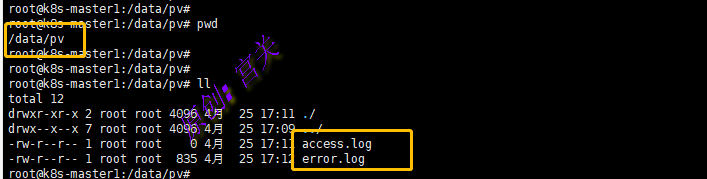
注意:pvc和pod要在相同的命名空间中,PVC是针对命名空间级别的
如果想要PVC直接绑定到指定的PV上,可通过如下配置实现:
- 在PV中通过claimRef来指定PVC的名字和所在的namespace
- 在PVC中通过volumeName来指定PV的名字
#PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
spec:
storageClassName: ""
claimRef:
name: foo-pvc #指定pvc名字
namespace: foo #指定pvc所在namespace
.......
#PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc #定义pvc名
namespace: foo #定义pvc所在的namespace
spec:
storageClassName: ""
volumeName: foo-pv #指定pv名字
.......
注意:这种指定名称的绑定方法不会考虑某些volume的绑定条件是否匹配,比如:节点亲和性
PVC也可以通过标签选择来匹配指定的PV,如下:
#PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
labels: #定义标签
app: test-pv
environment: production
spec:
storageClassName: ""
claimRef:
name: foo-pvc #指定pvc名字
namespace: foo #指定pvc所在namespace
.......
#PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc #定义pvc名
namespace: foo #定义pvc所在的namespace
spec:
storageClassName: ""
volumeName: foo-pv #指定pv名字
selector: #选择标签
matchLabels:
app: test-pv
environment: production
.......
注意:如果PVC使用了selector,那么无法使用storageClass来分配PV
一个PVC被多个pod或者pod中多个容器使用:
如果一个Pod中有两个容器,一个mysql容器,一个nginx容器,现在两个容器使用同一个PVC,此时可以通过使用子目录的形式来针对性使用,比如:PV的路径是/data/volume ,volume路径下有两个子目录mysql 和 html 目录,现在需要将mysql目录挂载到mysql容器的/usr/local目录下,另一个html目录挂载到nignx容器的/usr/share/nginx/目录下, 在pod中使用PVC的时候就可以通过subPath 来挂载子目录,如下:
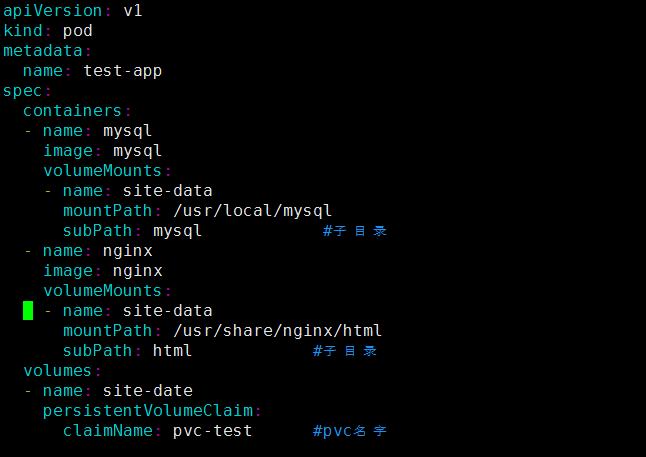
注:subPath中路径名称不能以”/ ” 开头,要用相对路径的形式
2、PV回收策略
当用户使用完卷时,可以从API中删除PVC对象,从而允许回收资源。回收策略(persistentVolumeReclaimPolicy)会告诉PV如何处理该卷。目前回收策略可以设置为:
- Retain:保留,该策略允许手动回收资源,当删除PVC时,PV仍然存在,PV中的数据也存在,PV被标记已释放,在清空数据之前不能被其他PVC使用,手动清理数据删除PV并重新创建PV才可以继续使用
- Recycle(已淘汰):回收,如果Volume插件支持,Recycle策略会对卷执行rm -rf清理该PV,并使其可用于下一个新的PVC,但是本策略将来会被弃用,目前只有NFS和HostPath支持该策略
- Delete:删除,如果Volume插件支持,删除PVC时会同时删除PV,动态卷默认为Delete,目前支持Delete的存储后端包括AWS EBS、GCEPD、Azure Disk、OpenStack Cinder等
3、PV访问策略
实际使用PV时,可能针对不同的应用会有不同的访问策略,比如某类Pod可以读写,某类Pod只能读,或者需要配置是否可以被多个不同的Pod同时读写等,此时可以使用PV的访问策略进行简单控制,目前支持的访问策略如下:
- ReadWriteOnce:可以被单节点以读写模式挂载,命令行中可以被缩写为RWO
- ReadOnlyMany:可以被多个节点以只读模式挂载,命令行中可以被缩写为ROX
- ReadWriteMany:可以被多个节点以读写模式挂载,命令行中可以被缩写为RWX
- ReadWriteOncePod:只能被一个Pod以读写的模式挂载,命令中可以被缩写为RWOP(1.22版本以上)
PV在创建时可以指定不同的访问策略,但是也要后端的存储支持才可以,一般情况下大部分块存储是不支持ReadWriteMany的,具体后端存储支持的访问模式可以参考官网:
https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/#access-modes注:一个pvc可以同时被多个pod挂载使用,pvc和pv为一对一
4、PVC扩容
PVC扩容机制在1.24版本达到stable阶段,目前只有CSI(容器存储接口,对接厂商存储的)和RBD(块设备接口)支持PVC扩容,如需要扩容PVC,需要在StorageClass中配置参数allowVolumeExpansion=true
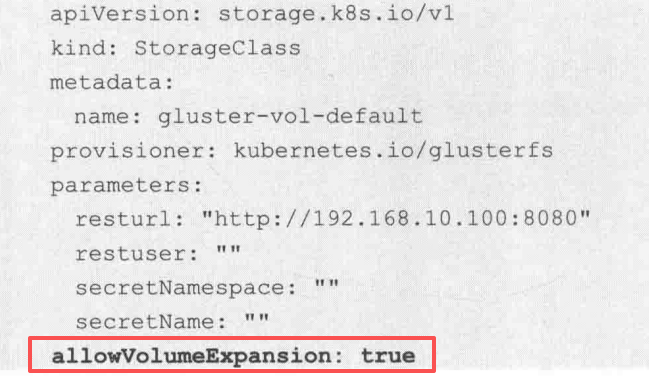
然后修改PVC的定义文件中的字段,resources.requests.storage的值为一个更大的值即可
5、PV生命周期的几个阶段:
- Available:可用状态,还未与PVC绑定
- Bound: 已与PVC绑定
- Released:与之绑定的PVC已被删除,但资源未回收,无法被其他PVC使用
- Failed: 自动资源回收失败
六、动态存储StorageClass
为什么需要StorageClass?
在一个大规模的Kubernetes集群里,可能有成千上万个PVC,这就意味着运维人员必须实现创建出多个PV,此外,随着项目的需要,会有新的PVC不断被提交,那么运维人员就需要不断的添加新的满足要求的PV,否则新的Pod就会因为PVC绑定不到PV而导致创建失败.而且通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求,而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了
StorageClass自动管理PV的生命周期,比如创建、删除、自动扩容等,StorageClass没有命名空间隔离性,属于集群级别的资源,通过它可以动态管理集群中的PV,这样Kubernetes管理员就无须浪费大量的时间在PV的管理中
在Kubernetes中,管理员可以只创建StorageClass“链接”到后端不同的存储,比如Ceph、GlusterFS、OpenStack的Cinder、其他公有云提供的存储等,之后有存储需求的技术人员,创建一个PVC指向对应的StorageClass即可,StorageClass会自动创建PV供Pod使用,也可以使用StatefulSet的volumeClaimTemplate自动分别为每个Pod申请一个PVC。
简单理解就是:不用手动创建pv了,创建storageclass后,在需要申请空间的时候,创建pvc,storageclass内部会自动创建和管理pv
动态卷创建的pv的回收策略默认就是delete,即删除pvc后,pv也一起删除
StorageClass一旦创建了,就不能修改,如果要修改,需要删除并新建
参数AllowVolumeExpansion参数如果设置为true,说明PV支持扩容, 可通过编辑增加PVC的空间大小来实现PV的扩容,此参数只支持扩容,不支持缩容
下面例子演示使用NFS作为后端存储,来创建storageclass,如果要使用NFS,需要先安装nfs-subdir-external-provisioner插件,通过Helm Chart离线安装步骤如下:
1、下载Helm Chart包,需要在有网络的机器上执行,如下:
wget https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/releases/download/nfs-subdir-external-provisioner-4.0.18/nfs-subdir-external-provisioner-4.0.18.tgz2、下载镜像,如下:
docker pull registry.cn-beijing.aliyuncs.com/pylixm/nfs-subdir-external-provisioner:v4.0.03、修改chart中的配置,如下:
# 解压Chart
tar -xzf nfs-subdir-external-provisioner-4.0.18.tgz
# 修改values.yaml
cd nfs-subdir-external-provisioner
vim values.yaml
# 修改以下配置:
nfs:
server: 192.168.1.100 # NFS服务器IP
path: /data/nfs # NFS共享路径
image:
repository: your-registry.com/nfs-subdir-external-provisioner
tag: v4.0.04、最后安装进去集群中,如下:
helm install nfs-provisioner . \
--namespace nfs-system \
--create-namespace \
-f values.yaml安装完成后会生成一个默认的storageclass,这个也可以使用,如果不用也可以自己创建,如下:
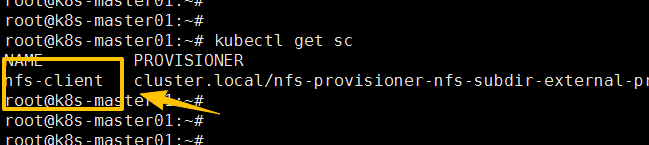
通过helm list -n nfs-system也可以看到已经安装的包,如图:

注:如果要卸载可以通过helm uninstall nfs-provisioner来完成
5、创建一个自定义的storageClass,yaml文件如下:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
# 设置为默认存储类(可选)
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: cluster.local/nfs-provisioner-nfs-subdir-external-provisioner
parameters:
# 路径模式:按命名空间和PVC名称创建子目录
pathPattern: "${.PVC.namespace}/${.PVC.name}"
# 删除PVC时的行为:delete-删除,retain-保留,archive-归档
onDelete: "delete"
# 可选:归档路径
archiveOnDelete: "false"
# 可选:指定nfs服务器和路径(如果Provisioner已配置则可省略)
# server: 192.168.1.100
# path: /data/nfs
# 卷绑定模式
volumeBindingMode: Immediate
# 回收策略
reclaimPolicy: Delete
# 允许卷扩容
allowVolumeExpansion: true- volumeBindingMode:绑定模式,默认值为Immediate,表示当pvc创建后,就动态创建pv与之绑定,如果有部分node节点无法访问存储,而创建的pod又调度到此节点上,可以导致调度失败,还有一个参数WaitForFirstConsumer,表示pvc和pv的绑定操作将等待第一个使用pvc的pod创建出来后进行,在pod所在的node上创建pv
- annotations:指定默认的StorageClass,供那些没有指定StorageClass的PVC使用,如果集群中多个storageclass都配置为默认StorageClass,那么等于没有默认StorageClass
- provisioner:指定存储插件,这个值需要通过kubectl describe po podname -n nfs-system |grep “PROVISIONER_NAME” 来查看
- pathPattern:会在存储中创建namespace/pvcname名字的子目录
- archiveOnDelete:是否归档,当设置为false时,删除 PVC 时直接删除 NFS 服务器上的数据目录,如果为true,删除 PVC 时将数据目录重命名为
archived-<目录名>进行归档
6、创建PVC,如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc
namespace: default
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi创建后在存储目录里就可以看到已经根据namespace/pvc-name来创建目录,如图:

7、创建pod,并使用PVC,如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: nfs-volume
mountPath: /usr/share/nginx/html
subPath: html
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: test-pvc- subPath:将pvc的子目录html挂载到/usr/share/nginx/html下
创建完成后在存储的test-pvc目录下会自动创建html目录,如图:
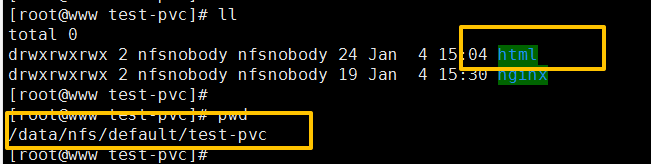
在html目录下创建index.html,去pod的容器中查看,可以看到文件和内容都已存在,如图:
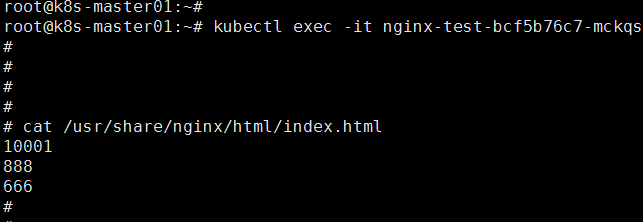
注意:在 Kubernetes 中,每个 StorageClass 只能关联一个 provisioner。如果你有多个 NFS 服务器(不同 IP、不同共享路径、不同配置),需要为每个 NFS 后端部署独立的 nfs-provisioner,为每个 provisioner 创建对应的 StorageClass,在 PVC 中指定不同的 storageClassName 来选择不同的 NFS 后端


