k8s使用常见问题
1、创建ingress服务的时候,出现错误信息如下:
Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": Post
https://ingress-nginx-controller-admission.kube-system.svc:443/networking/v1beta1/ingresses?
timeout=10s: dial tcp 10.0.0.5:8443: connect: connection refused
原因:安装完ingress controller后,将其删除并且删除了命令空间,但是没有删除ValidatingWebhookConfiguration,再次创建ingress服务的时候就会报错
解决方案:
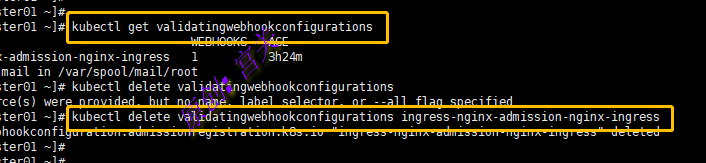
通过命令查看webhook,并删除,如图:
2、机器断电重启后,apiserver起不来,etcd报错如下:
panic: freepages: failed to get all reachable pages (page 113: multiple references)原因:断电导致etcd数据损坏
解决方案:恢复备份的etcd数据,可参考k8s之etcd的备份与回恢复 – IT运维 (blog.ywdevops.cn)
3、机器意外重启或其余原因导致calico-controller起不来,同时pod也无法创建和删除,查看报错信息如下:
network: error getting ClusterInformation: connection is unauthorized,networkPlugin cni failed to teardown
Failed to verify datastore error=Get "https://10.96.0.1:443/apis/crd.projectcalico.org/v1/clusterinformations/default": context deadline exceeded原因:calico连接Kubernetes API datastore失败,无法连接,calico为Pod分配的IP是存储在kubernetes api datastore中,如果出现异常情况,比如node节点down掉,上面的Pod没有驱逐,那么就会有存留的ip存储在api datastore中,再次启动时残留的数据就会对pod的启动产生影响,导致无法启动
解决方案:将所有的calico相关的pod全部删掉,那么通过deployment规则会自动重新启动新的pod,从重新分配ip地址,问题解决