夜莺监控v5版本与VictoriaMetrics部署
本例子中以v5.8.0版本为例,中文手册地址:夜莺中文手册
基础环境:
- mysql (需要设置主机连接为%,否则启动报错)
- redis
- prometheus(以prometheus作为时序数据库),安装参考:prometheus二进制安装 – IT运维 (blog.ywdevops.cn)
1、下载v5.8.0,执行命令如下:
https://github.com/ccfos/nightingale/releases2、执行如下命令创建目录并解压文件:
mkdir -p /usr/local/n9e
tar xf n9e-5.8.0.tar.gz -C /usr/local/n9e3、导入初始化sql文件,执行如下命令:
mysql -u root -p < docker/initsql/a-n9e.sql4、修改配置文件中redis、MySQL、Prometheus地址,如果都在本机就127.0.0.1,如图:

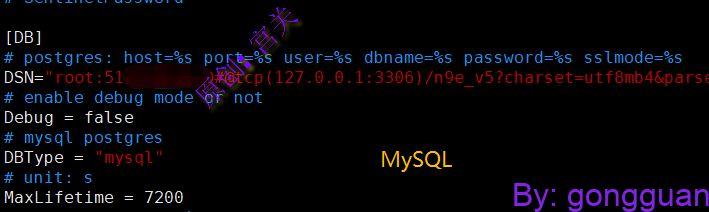
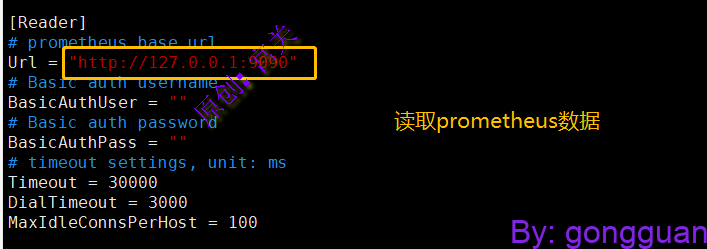

5、拷贝服务启动文件到启动目录下,并修改内部路径:
cp -a /usr/local/n9e/etc/service/{n9e-webapi.service,n9e-server.service} /lib/systemd/system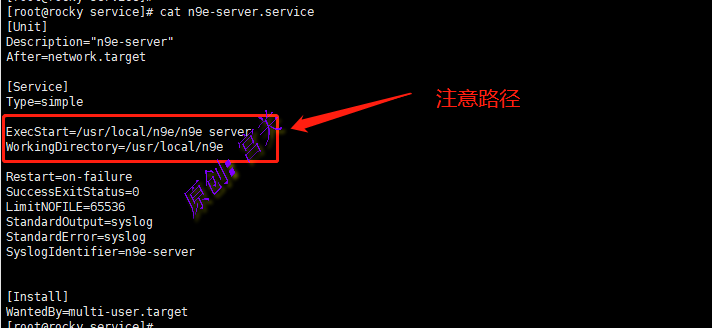
6、执行如下命令启动:
systemctl daemon-reload
systemctl enable n9e-server --now
systemctl enable n9e-webapi --now7、浏览器访问webapi的端口(默认为18000),即可访问页面,如图:
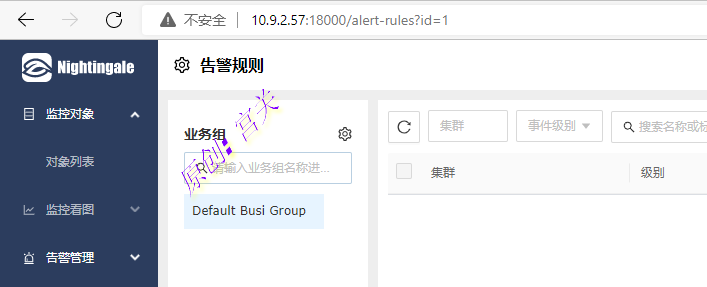
注:账号密码为root root.2020
修改时序数据库为VictoriaMetrics
VictoriaMetrics 是一个快速、经济高效且可扩展的监控解决方案和时间序列数据库,基本支持Prometheus配置文件、PromQL、各类API、数据格式等
优点:
- 远程存储:可作为单一或多个Prometheus的远程存储
- 安装简单:单节点架构一条命令就可以部署完毕,集群稍微复杂
- 兼容性:PromQL兼容和增强的MetricsQL
- Grafana兼容:VM可替换Grafana的Prometheus数据源(线上数据源直接替换后100%兼容)
- 低内存:更低的内存占用,官方对比Prometheus,可以释放7倍左右内存空间
- 高压缩比:提供存储数据高压缩,官方说可以比Prometheus减少7倍的存储空间
- 高性能:查询性能比Prometheus更快
- 支持水平扩容&HA:基于VM集群版实现
- 支持多租户:主要针对集群版
缺点:
- 图形化做的不好,虽然有vmui,但功能很少
- 告警功能需要单独配置vmalert,而且vmalert只有api管理和查看,暂时没用图形界面
- 没有类似Prometheus的WAL日志,突然故障可能会丢失部分数据
单机版部署:
1、首先下载VM,下载地址:
https://github.com/VictoriaMetrics/VictoriaMetrics/2、解压,将二进制包移动到合适位置,如下:
tar xf victoria-metrics-amd64-v1.77.2.tar.gz
mkdir -p /usr/local/victoria-metrics-prod
mv victoria-metrics-prod /usr/local/victoria-metrics-prod3、启动VictoriaMetrics,执行命令如下:
#可定义在脚本中
nohup /usr/local/victoria-metrics-prod/victoria-metrics-prod \
-storageDataPath /usr/local/victoria-metrics-prod/vmstorage-data \
-httpListenAddr :8428 \
-search.maxSeries 100000 \
-loggerTimezone Asia/Shanghai &> victoria-metrics.log &
参数说明:
-storageDataPath参数指定数据存储的目录。默认为victoria-metrics-data-retentionPeriod参数指定数据保存的时长。默认为1 month-httpListenAddr参数指定监听的 HTTP 套接字。默认为:8428-loggerTimezon参数指定日志的时区,默认为UTC. 建议设置为Asia/Shanghai-maxInsertRequestSize参数限制 Prometheus remote_write API 的请求大小。默认为33554432 byte. 支持可选的单位为KB, MB, GB, KiB, MiB, GiB-promscrape.config参数指定 Prometheus 配置文件路径-selfScrapeInstance参数设置抓取自身 metrics 时,instance标签的值。默认self-selfScrapeInterval参数设置抓取自身 metrics 的时间间隔-selfScrapeJob参数设置设置抓取自身 metrics 时,instance标签的值。默认victoria-metrics- -search.maxSeries:设置查询的metircs数,默认是10000,可手动设置为100000或者更多
4、修改n9e的server.conf文件,将读取和写入的时序数据库接口改为VM接口,如图:
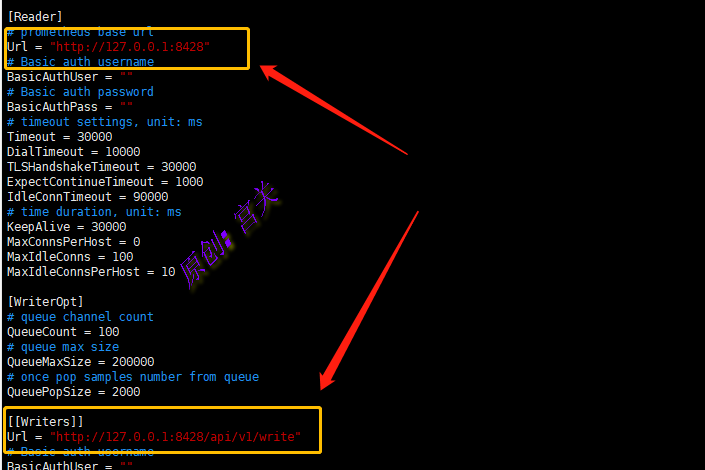
5、修改webapi.conf,将读取时序数据库用于展示的接口修改为VM接口,如图:
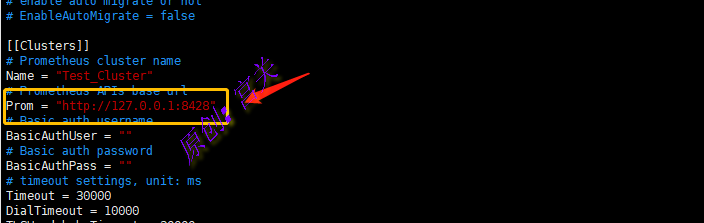
注:上图中的Name的值要与server.conf中ClusterName配置的一样,默认为Default
6、停掉prometheus,重启n9e-server、n9e-webapi,查看监控指标,如图:
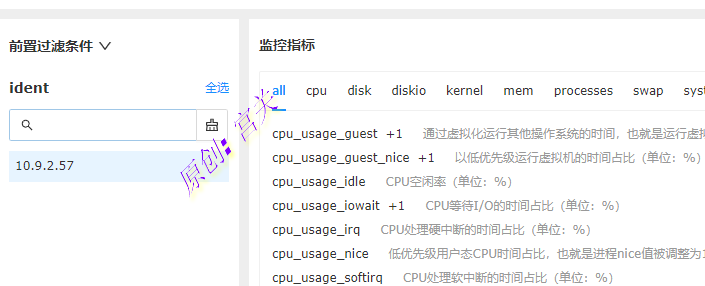
注:如果看不到监控指标,并且vm日志里提示如下内容:
error in "/api/v1/label/__name__/values?start=1654740213&end=1654743813&match%5B%5D=%7Bident%3D~%2210.9.2.247%22%7D": cannot obtain label values for "__name__", match[]=["{ident=~\"10.9.2.247\"}"], start=1654740213000, end=1654743813000: cannot fetch data for "MinTimestamp=2022-06-09 02:03:33 +0000 UTC, MaxTimestamp=2022-06-09 03:03:33 +0000 UTC, TagFilters=[\n{Key=\"ident\", Value=\"10.9.2.247\", IsNegative: false, IsRegexp: true}\n]": search error after reading 0 data blocks: error when searching for tagFilters=[{ident=~"10.9.2.247"}] on the time range [2022-06-09 02:03:33 +0000 UTC - 2022-06-09 03:03:33 +0000 UTC]: error when searching tsids: the number of matching timeseries exceeds 10000; either narrow down the search or increase -search.max* command-line flag values at vmselect
此日志说明VM返回的metircs数量已经超过默认设置的10000,此时需要修改数量,可在启动时候添加参数-search.maxSeries,并设置合理的值即可
更多参数可通过victoria-metrics-prod -h查看


