通过夜莺监控kube-apiserver
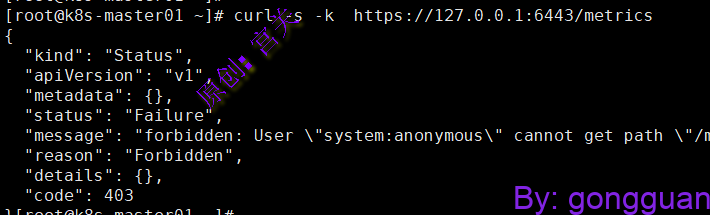
apiserver提供了metircs接口用来暴露数据,但是默认情况下是没有权限访问的,需要通过token的方式请求,不加token请求如下:
1、创建角色和权限设置,先创建命名空间,然后执行创建命令,如下:
kubectl create ns monitor---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf-clusterrole
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- nodes/stats
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: categraf-serviceaccount
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf-clusterrolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf-clusterrole
subjects:
- kind: ServiceAccount
name: categraf-serviceaccount
namespace: monitor
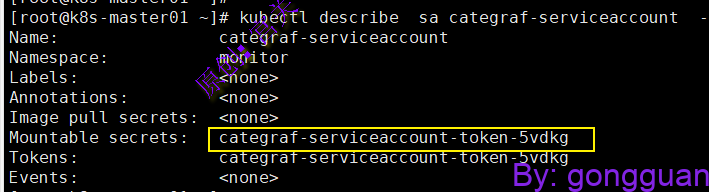
2、查看categraf-serviceaccount的信息,可以看到默认生成的token名,如图:
kubectl describe sa categraf-serviceaccount -n monitor
获取token的值,如下命令:
kubectl describe secret categraf-serviceaccount-token-5vdkg -n monitor3、再次通过token,进行请求,如图:
token="内容"
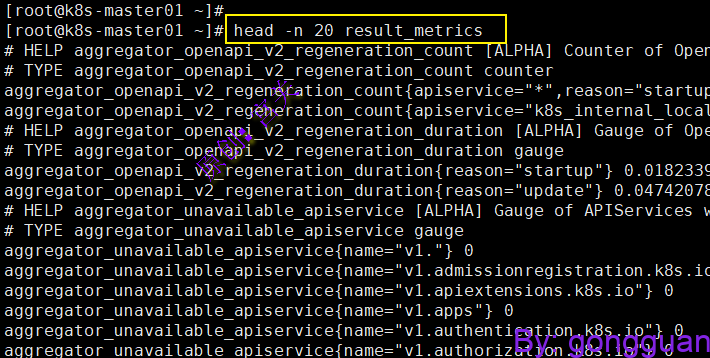
curl -s -k -H "Authorization: Bearer $token" https://127.0.0.1:6443/metrics > result_metrics已经可以正常请求到数据,如图:
如果 APIServer 是二进制方式部署直接通过Categraf 的 Prometheus 插件来抓取就可以了。如果 APIServer 是部署在 Kubernetes 的容器里,可使用服务发现机制来做抓取数据
本例子中使用prometheus的agent mode模式来抓取数据,Prometheus 新版本(v2.32.0)支持了 agent mode 模式,即把 Prometheus 进程当做采集器 agent,采集了数据之后通过 remote write 方式传给夜莺服务端
4、部署prometheus agent mode
(1)、首先准备prometheus所需要的配置文件prometheus.yml,做成ConfigMap,如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: monitor
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kube_apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https #此三个值对应上面的source_labels中的三个字段
remote_write:
- url: 'http://10.9.2.247:19000/prometheus/v1/write' #夜莺服务端地址
上面配置中服务发现使用的是endpoints,匹配规则有三点(通过 relabel_configs 的 keep 实现)
__meta_kubernetes_namespaceendpoint 的 namespace 是default__meta_kubernetes_service_nameservice name是kubernetes__meta_kubernetes_endpoint_port_nameendpoint 的 port_name 是https
(2)、部署 Prometheus agent,要把 Prometheus 进程当做 agent 来用,需要启用这个 feature,通过命令行参数 --enable-feature=agent 即可启用,通过deployment来部署,如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-agent
namespace: monitor
labels:
app: prometheus-agent
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-agent
template:
metadata:
labels:
app: prometheus-agent
spec:
serviceAccountName: categraf-serviceaccount #注意这个值需要与上面创建的相同
containers:
- name: prometheus
image: prom/prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--enable-feature=agent" #启用插件
ports:
- containerPort: 9090
resources:
requests:
cpu: 500m
memory: 500M
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420 #十进制表示法,八进制为644
name: prometheus-agent-conf
- name: prometheus-storage-volume
emptyDir: {}
创建完成后,在夜莺服务端的即时看图里可以看到apiserver的指标,如图:
关键指标:
# HELP apiserver_request_duration_seconds [STABLE] Response latency distribution in seconds for each verb, dry run value, group, version, resource, subresource, scope and component.
# TYPE apiserver_request_duration_seconds histogram
apiserver响应的时间分布,按照url 和 verb 分类
一般按照instance和verb+时间 汇聚
# HELP apiserver_request_total [STABLE] Counter of apiserver requests broken out for each verb, dry run value, group, version, resource, scope, component, and HTTP response code.
# TYPE apiserver_request_total counter
apiserver的请求总数,按照verb、 version、 group、resource、scope、component、 http返回码分类统计
# HELP apiserver_current_inflight_requests [STABLE] Maximal number of currently used inflight request limit of this apiserver per request kind in last second.
# TYPE apiserver_current_inflight_requests gauge
最大并发请求数, 按mutating(非get list watch的请求)和readOnly(get list watch)分别限制
超过max-requests-inflight(默认值400)和max-mutating-requests-inflight(默认200)的请求会被限流
apiserver变更时要注意观察,也是反馈集群容量的一个重要指标
# HELP apiserver_response_sizes [STABLE] Response size distribution in bytes for each group, version, verb, resource, subresource, scope and component.
# TYPE apiserver_response_sizes histogram
apiserver 响应大小,单位byte, 按照verb、 version、 group、resource、scope、component分类统计
# HELP watch_cache_capacity [ALPHA] Total capacity of watch cache broken by resource type.
# TYPE watch_cache_capacity gauge
按照资源类型统计的watch缓存大小
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
每秒钟用户态和系统态cpu消耗时间, 计算apiserver进程的cpu的使用率
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
apiserver的内存使用量(单位:Byte)
# HELP workqueue_adds_total [ALPHA] Total number of adds handled by workqueue
# TYPE workqueue_adds_total counter
apiserver中包含的controller的工作队列,已处理的任务总数
# HELP workqueue_depth [ALPHA] Current depth of workqueue
# TYPE workqueue_depth gauge
apiserver中包含的controller的工作队列深度,表示当前队列中要处理的任务的数量,数值越小越好
例如APIServiceRegistrationController admission_quota_controller