ceph集群的使用
一、文件存储CephFs
注意:集群需要安装mds才可以,安装参考:分布式存储之ceph原理与部署 – IT运维 (blog.ywdevops.cn)
一个 Ceph 文件系统需要至少两个存储池,一个用于存储数据、一个用于存储元数据,注意元数据池中的任何数据丢失都可能导致整个文件系统无法访问,对元数据池使用较低延迟的存储(例如SSD),因为这将直接影响在客户端上观察到的文件系统操作的延迟
1、首先在服务端创建两个存储池,执行命令如下:
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_metadata 128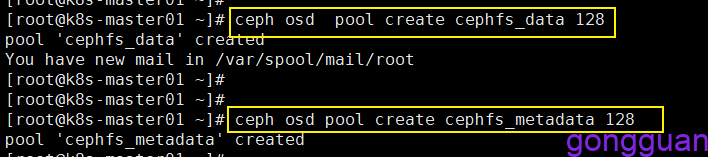
2、创建文件系统,执行命令如下:
ceph fs new cephfs cephfs_metadata cephfs_data
通过如下命令查看创建的CephFS,如下:
ceph fs ls
查看cephfs状态,可以看到一个为活跃状态,两个为备份状态,如图:
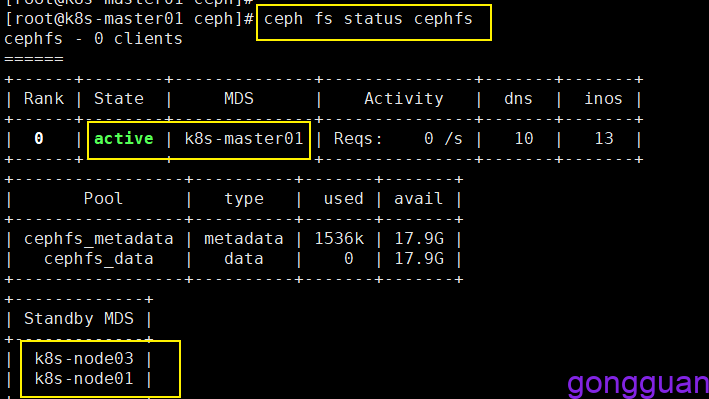
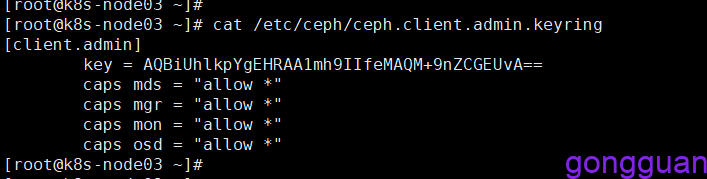
3、查看客户端挂载时需要的秘钥,下图中的key的值,如图:
4、通过客户端挂载,有两种方法
方法一 、 通过内核驱动(mount)
在需要挂载的机器上安装客户端工具,执行命令如下:
yum -y install ceph-common创建挂载目录,执行命令挂载:
mkdir -p /data/cephfs
#挂载命令中的name的值就是上图中client.admin后面的admin的值,secret的key值也可以写进文件admin.key中,然后通过secretfile来指定,如:secretfile=/data/admin.key
mount -t ceph 10.9.2.250:6789,10.9.2.251:6789,10.9.2.253:6789:/ /data/cephfs -o name=admin,secret=AQBiUhlkpYgEHRAA1mh9IIfeMAQM+9nZCGEUvA==
测试:
向/data/cephfs目录 cp 一个文件,如图:
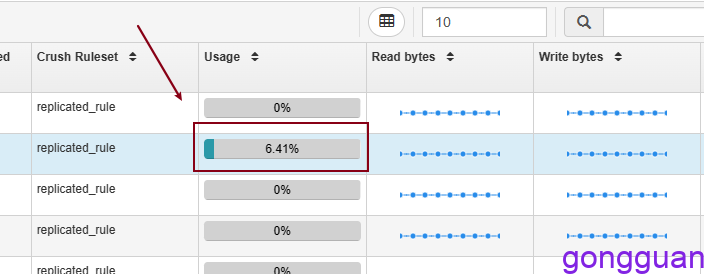
通过页面或者ceph -h 可以看到存储空间已经使用,如图:
方法二、通过ceph-fuse
1、先配置ceph.repo源,内容如下:
[ceph-nautilus]
name=ceph-nautilus
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
[ceph-nautilus-noarch]
name=ceph-nautilus-noarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
2、安装ceph-fuse,执行命令如下:
yum -y install ceph-fuse3、将ceph集群中/etc/ceph/ceph.client.admin.keyring文件放在要挂载机器的/etc/ceph目录下,如图:

4、执行如下命令挂载,将cephfs挂载到/data/furefs目录下,如下:
ceph-fuse -n client.admin -m 10.9.2.250:6789,10.9.2.251:6789,10.9.2.253:6789 /data/furefs/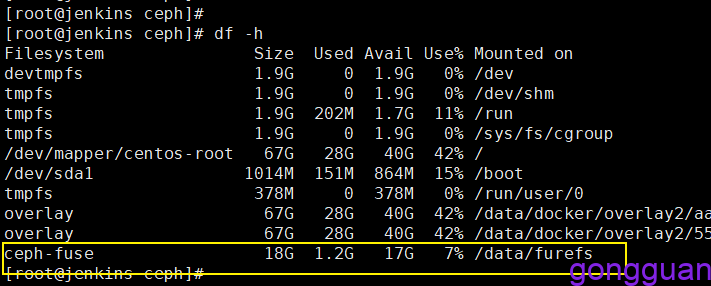
进入目录中,查看之前集群中的文件是否存在,如图:

从上图看出,之前向集群中添加的文件挂载到新目录后还是存在的
如果要卸载挂载点,可使用命令如下:
fusermount -u /data/furefs #如果磁盘繁忙,就使用fusermount -zu /data/furefs多用户多目录挂载并控制权限
上面的挂载是使用默认情况下的admin用户来挂载的,此用户权限很大,实际使用中不建议通过此用户挂载,应该详细的根据不同用户使用不同的目录,并进行权限划分,用户只对自己的目录有权限,其余目录无权限
1、新建用户client.test,此用户只对/abcd具有读写权限,其余路径只读,命令如下:
#mds后的第一个allow r表示对任何路径只读,第二个allow 表示对路径abcd可读写
#osd后的allow表示对存储池cephfs_data可读写
#mon后的allow r表示对mon只读
ceph auth get-or-create client.test mon 'allow r' mds 'allow r,allow rw path=/abcd' osd 'allow rw pool=cephfs_data'注意:每个组件的权限都可以设置多个allow,中间逗号分开,比如上面的mds中就有多个allow
2、获取用户client.test对应的密钥环,命令如下:
ceph auth get client.test -o /etc/ceph/ceph.client.test.keyring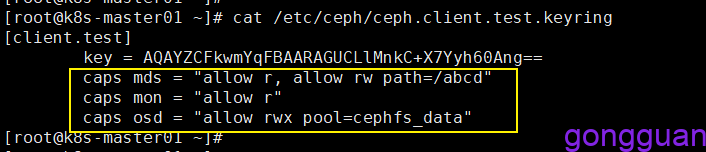
3、通过用户test和key将根路径挂载到/data/cephfs,如下:
mount -t ceph 10.9.2.250:6789,10.9.2.251:6789,10.9.2.253:6789:/ /data/cephfs -o name=test,secret=AQAYZCFkwmYqFBAARAGUCLlMnkC+X7Yyh60Ang==挂载完成后,进入路径/data/cephfs,可以看到路径下除了之前上传的文件外,没有任何文件夹,如图:

用户test对根目录无任何权限,因此我们在上面权限管控中指定了test只对/abcd具有读写权限,其余路径只有只读权限,如图:
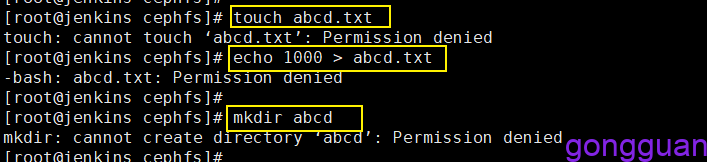
但是cephfs中默认是没有这个目录abcd,解决方案:可先通过admin用户在任何一台机器或者管理机器上,先将cephfs的根目录/挂载出来,然后在根目录下创建所需要的项目目录即可,如果有多个项目,就要创建多个目录
mkdir -p /data/temp #创建一个临时目录
#通过admin用户将cephfs根目录挂载出来,admin为管理员,对整个集群有操作权限
mount -t ceph 10.9.2.250:6789,10.9.2.251:6789,10.9.2.253:6789:/ /data/temp/ -o name=admin,secret=AQBiUhlkpYgEHRAA1mh9IIfeMAQM+9nZCGEUvA==
#在根目录下创建所需要的项目文件夹
mkdir -p /data/temp/abcd执行完成后再次回到挂载机器的/data/cephfs目录下,可以看到abcd目录已经出现,进入路径abcd下,测试是否有创建写入删除权限,如图:
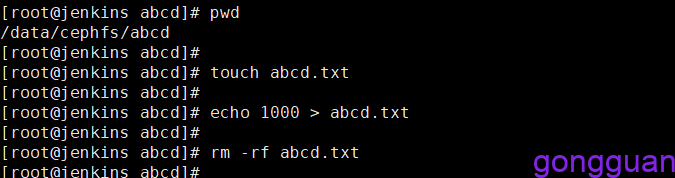
从上图可以看出,通过test挂载后,对目录abcd文件具有创建读写和删除权限
我们在通过admin用户在根目录下创建一个文件夹gongguan,再次回到上图中的挂载机器路径下/data/cephfs可以看到此目录,如图:
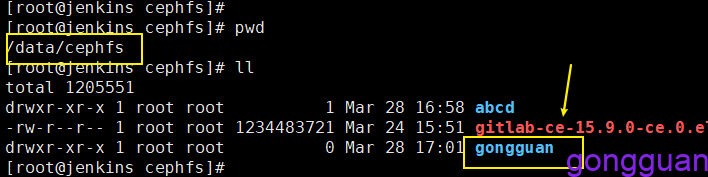
进入目录gongguan,执行创建写入删除,可以发现,没有权限,但是具有读的权限,如图:
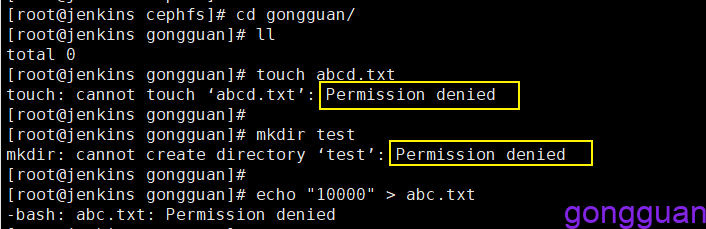
有个小问题:如果gongguan目录中本来已经存在文件,通过echo可以向里面写输入,不知道是不是bug
注意注意:ceph.client.admin.keyring文件不可出现在任何客户端中,因此此文件具有超级管理员权限,有了此文件即可操作集群各种资源
二、对象存储rgw
对象存储是指可通过GET、PUT、DEL和其他扩展,向存储服务上传下载数据
对象存储进程默认运行的端口是7480,查看如下:

如果想修改为指定端口,可编辑配置文件ceph.conf,添加内容如下:
[client.rgw.ceph-node1]
rgw_frontends = "civetweb port=80"通过命令curl http://localhost:7480测试,如果显示如下表示对象存储环境是好的,如下:
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>本例子演示通过S3访问RGW
1、首先创建模拟用户,命令如下:
radosgw-admin user create --uid s3-user-demo --display-name "s3Demo" --system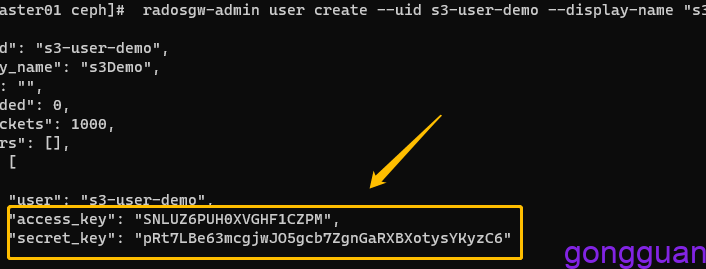
access_key和secret_key要记住,如果忘记了,可通过命令查询:
radosgw-admin user info --uid s3-user-demo2、使用ceph sdk访问ceph集群,使用官网的python脚本,如图:
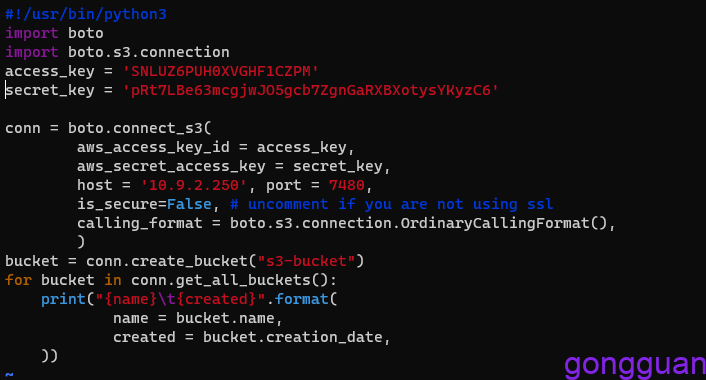
#!/usr/bin/python3
import boto
import boto.s3.connection
access_key = 'SNLUZ6PUH0XVGHF1CZPM'
secret_key = 'pRt7LBe63mcgjwJO5gcb7ZgnGaRXBXotysYKyzC6'
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = '10.9.2.250', port = 7480,
is_secure=False, # uncomment if you are not using ssl
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket("s3-bucket")
for bucket in conn.get_all_buckets():
print("{name}\t{created}".format(
name = bucket.name,
created = bucket.creation_date,
))3、执行命令创建存储桶s3-bucket,如图:

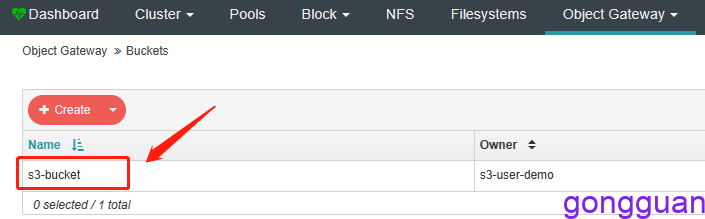
4、安装命令行工具s3cmd,执行命令如下:
yum -y install s3cmd5、配置命令行工具:
[root@k8s-master01 tmp]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key: SNLUZ6PUH0XVGHF1CZPM #填写上面的
Secret Key: pRt7LBe63mcgjwJO5gcb7ZgnGaRXBXotysYKyzC6
Default Region [US]: #此处默认为US即可
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [s3.amazonaws.com]: 10.9.2.250:7480
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 10.9.2.250:7480
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password: 123456789
Path to GPG program [/usr/bin/gpg]: #默认
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [Yes]: no
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name: #默认,直接回车
New settings:
Access Key: SNLUZ6PUH0XVGHF1CZPM
Secret Key: pRt7LBe63mcgjwJO5gcb7ZgnGaRXBXotysYKyzC6
Default Region: cn
S3 Endpoint: 10.9.2.250:7480
DNS-style bucket+hostname:port template for accessing a bucket: 10.9.2.250:7480
Encryption password: 5182086abcD
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name:
HTTP Proxy server port: 0
Test access with supplied credentials? [Y/n] y
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Success. Encryption and decryption worked fine :-)
Save settings? [y/N] y
Configuration saved to '/root/.s3cfg'6、列出存储桶,创建存储桶,如图:
s3cmd mb s3//new-bucket //创建存储桶
s3cmd ls //列出存储桶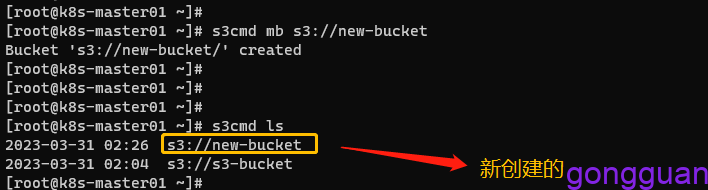
7、向存储桶中上传2个文件,如图:

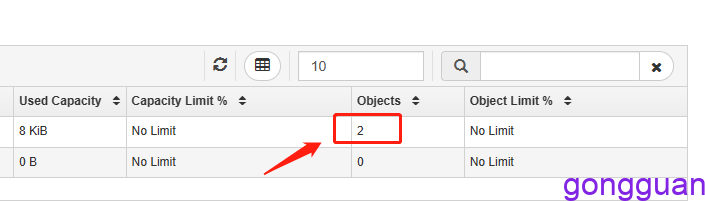
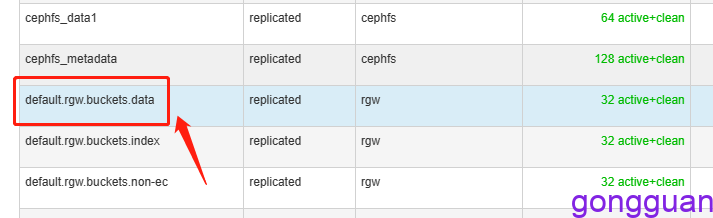
数据实际是存放在了系统自动创建的存储池中,如图:
常用命令:
s3cmd put secret.yml s3://new-bucket #上传文件
s3cmd get s3://new-bucket/secret.yml #下载文件
s3cmd mb s3://new-bucket #创建存储桶
s3cmd rb s3://new-bucket #删除存储桶
s3cmd ls s3://new-bucket #列出存储桶内容
s3cmd put dir s3://new-bucket --recursive #上传目录到存储桶
s3cmd info s3://new-bucket/secret.yml #查看文件信息
s3cmd du -H s3://new-bucket #查看存储桶占用空间
s3cmd del s3://new-bucket/secret.yml #删除存储桶中内容
三、块存储(RBD)
RBD是ceph集群向外提供存储服务的一种接口,该接口是基于ceph底层存储集群librados api构建的接口;即RBD是构建在librados之上向外提供存储服务的;对于客户端来说RBD主要是将rados集群之上的某个存储池里的空间通过librados抽象为一块或多块独立image,这些Image在客户端看来就是一块块硬盘
与cephfs和rgw一样,rbd也需要创建存储池,然后将此存储池初始化为一个RBC存储才能正常使用
1、在ceph服务端创建并初始化存储池
ceph osd pool create rbd-pool 64 #创建存储池
ceph osd pool application enable rbd-pool rbd #启用rbd应用
rbd pool init -p rbd-pool #初始化存储池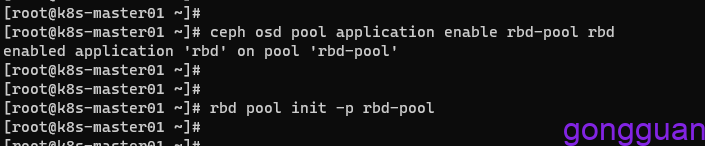
2、创建镜像并查看镜像,如图:
rbd create --size 5G rbd-pool/image-test #创建大小为5G的镜像
rbd ls -p rbd-pool #查看创建的镜像
查看镜像的详细信息,如图:
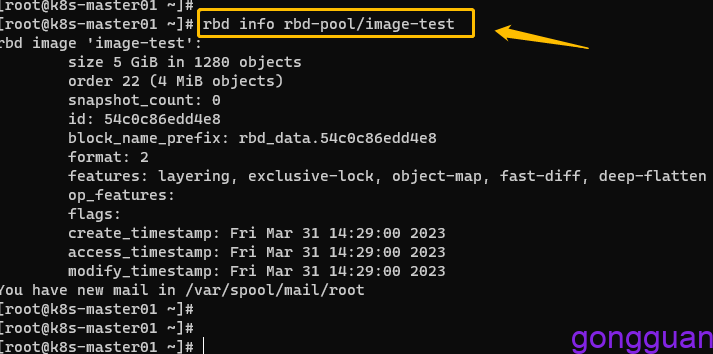
- size 5 GiB in 1280 objects:5G大小空间被分割为1280个对象,单个对象默认为4M
- order 22 (4 MiB objects):块大小(条带)的标识序号,有效范围为12-25,分别对应着4K-32M之间的大小,22=10+10+2,即2的10次方乘以2的10次方乘以2的2次方,2的10次方字节就是1024B,即1k,如果order为10,则块大小为1k,由此逻辑图推算22就是4M
- snapshot_count: 快照数量为
- block_name_prefix:表示当前image相关的object的名称前缀
- format:表示image的格式,2表示v2
- features:表示当前image启用的功能特性,其值是一个以逗号分隔的字符串列表,layering: 是否支持克隆;striping: 是否支持数据对象间的数据条带化;exclusive-lock: 是否支持分布式排他锁机制以限制同时仅能有一个客户端访问当前image;object-map: 是否支持object位图,主要用于加速导入、导出及已用容量统计等操作,依赖于exclusive-lock特性;fast-diff: 是否支持快照间的快速比较操作,依赖于object-map特性;deep-flatten: 是否支持克隆分离时解除在克隆image时创建的快照与其父image之间的关联关系;
上图中的features中的特性为默认特性,如果要开启或者关闭其中的某些特性可执行如下命令:
#关闭fast-diff 和 deep-flatten特性
rbd feature disable rbd-pool/image-test fast-diff deep-flatten3、创建客户端用户用于连接ceph集群,如下:
ceph auth get-or-create client.user_rbd mon 'allow r' osd 'allow rw pool=rbd-pool'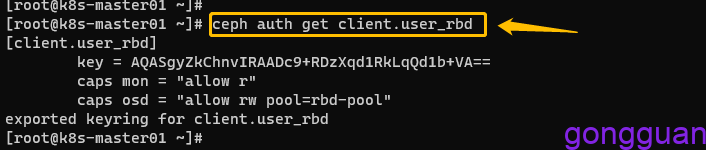
导出keyring文件用于认证连接集群:
ceph auth get client.user_rbd -o /etc/ceph/ceph.client.user_rbd.keyring4、将keyring文件和ceph.conf文件发送到客户端机器路径,如下:
scp /etc/ceph/ceph.client....keyring /etc/ceph/ceph.conf ip:/etc/ceph/
#注意:客户端不能有ceph.client.admin.keyring,此文件权限太大5、在客户端上通过用户user_id查看集群信息,如图:
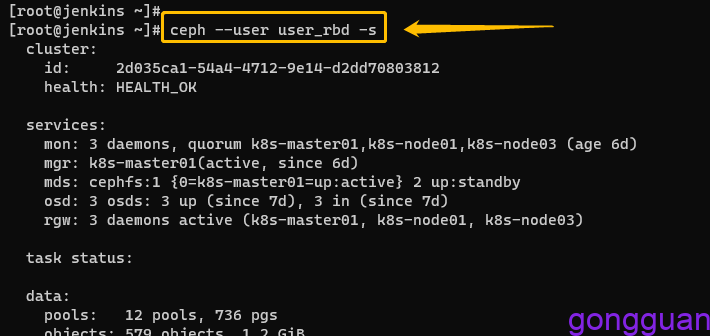
注意:是在客户端执行,不是ceph服务端,能查到说明连接集群成功
6、在客户端将rbd镜像映射到本地
映射之前我们先查看本机的磁盘情况,执行lsblk,如图:
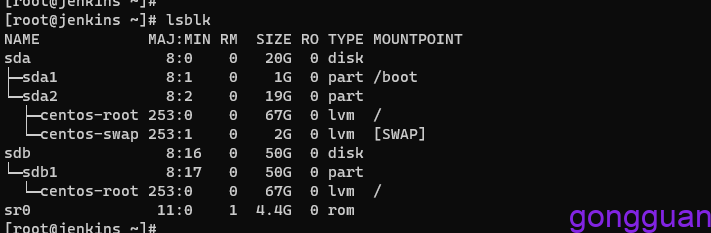
执行命令进行映射,如下:
rbd map --user user_rbd rbd-pool/image-test #将此命令写入到/etc/rc.d/rc.local中开启自动映射如果执行后出现如下错误:
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd-pool/image-test object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address原因:客户端内核过低,3.10内核仅支持layering特性,可将内核升级高于3.10即可,再次挂载,如图:

再次通过lsblk查看映射后的机器磁盘情况,多了一个rbd0,如图:
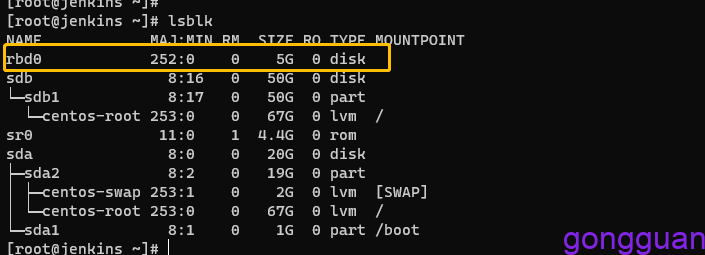
7、格式化后挂载设备,命令如下:
mkfs.xfs /dev/rbd0
mkdir -p /data/rbd
mount /dev/rbd0 /data/rbd #注意需要写入到/etc/rc.d/rc.local中实现开机自动挂载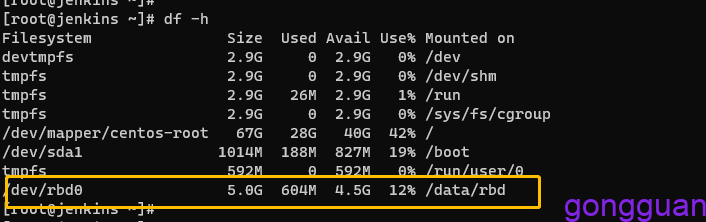
常用命令:
rbd create --size 3G rbd-pool/image-test1 #创建一个3G大小的镜像image-test1
rbd ls -p rbd-pool #查看镜像名称
rbd ls -p rbd-pool -l #查看镜像名称和大小以及版本
rbd info rbd-pool/image-test1 #查看镜像详细信息
rbd feature disable/enable rbd-pool/image-test1 fast-diff #关闭启用相关特性
rbd map --user user_rbd rbd-pool/image-test1 #映射镜像到本机设备
rbd showmapped #查看映射镜像
rbd unmap rbd-pool/image-test1 #手动断开映射
rbd unmap -o force /dev/rbd0 #强制卸载
rbd resize --size 6G rbd-pool/image-test1 #调整镜像大小为6G
rbd resize --size 5G rbd-pool/image-test1 --allow-shrink #缩小镜像大小为5G
rbd rm rbd-pool/image-test1 #删除镜像,不推荐
rbd trash mv rbd-pool/image-test1 #将镜像image-test1移入回收站中
rbd trash ls rbd-pool #查看存储池回收站信息
rbd trash restore --pool rbd-pool --image-id 54cfcf94e4e38 #从回收站恢复指定id镜像到池中
rbd trash rm --pool rbd-pool --image-id 54cfcf94e4e38 #删除回收站中指定id镜像
rbd snap create rbd-pool/image-test@snap #给镜像image-test创建快照,snap为快照名
rbd snap rollback rbd-pool/image-test@snap #回滚镜像image-test的快照snap
rbd snap limit set rbd-pool/image-test --limit 10 #限制快照数量为10
rbd snap limit clear rbd-pool/image-test #解除快照限制
rbd snap list rbd-pool/image-test #快照列表
rbd snap rm rbd-pool/image-test@snap #删除快照,以异步方式删除数据不能立即释放磁盘空间
rbd snap purge rbd-pool/image-test #删除一个image的所有快照
rbd snap protect rbd-pool/image-test@snap #快照保护,不保护无法克隆
rbd snap unprotect rbd-pool/image-test@snap #取消快照保护
rbd clone rbd-pool/image-test@snap rbd-pool/image-test2 #快照克隆,要先进行保护后才可以克隆
rbd children rbd-pool/image-test@snap #列出快照克隆后的子项

