rabbitmq集群搭建
为了确保高可用性和容错性,RabbitMQ 集群通常至少需要3个节点。使用至少3个节点的集群可以确保在一个节点出现故障时,集群仍然可以继续正常运行。通过在多个节点之间分配数据和负载,RabbitMQ 集群可以提供更高的可用性和性能。
在一个仅有两个节点的集群中,如果一个节点发生故障,集群将无法继续正常工作。因此,为了避免单点故障,至少需要3个节点。此外,选择奇数个节点有利于投票决策,避免在节点故障时出现平局的情况
官方说明的形成rabbitmq集群主要有以下方法:
- 通过在配置文件中列出集群节点以声明方式
- 以声明方式基于DNS的发现
- 以声明方式使用AWS(EC2)实例发现
- 声明式使用kubernetes发现
- 以声明方式基于etcd的发现(通过插件)
- 手动使用rabbitmqctl
集群部署
本例子演示通过三台机器上的docker容器来运行rabbitmq,如下:
| 宿主IP | 容器内主机名 | rabbitmq节点名称(计算生成) |
| 192.168.49.224 | rabbitmq1 | rabbit@rabbitmq1 |
| 192.168.49.186 | rabbitmq2 | rabbit@rabbitmq2 |
| 192.168.49.83 | rabbitmq3 | rabbit@rabbitmq3 |
1、在每台机器上创建目录/data/rabbitmq,并新建hosts文件,内容如下:
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.49.224 rabbitmq1
192.168.49.186 rabbitmq2
192.168.49.83 rabbitmq3注:这个hosts文件其实是先运行容器后,从里面把/etc/hosts文件拷贝出来,添加了rabbitmq的host后又挂载进去的,如果不这样做,直接修改容器里的/etc/hosts,一旦重启了容器,/etc/hosts配置内容会消失
2、在49.224机器上创建rabbitmq1容器,命令如下:
docker run -itd --name rabbitmq1 \
--hostname rabbitmq1 -p 4369:4369 \
-p 15672:15672 -p 5672:5672 \
-p 25672:25672 \
-v /data/rabbitmq/hosts:/etc/hosts \
-v /etc/localtime:/etc/localtime rabbitmq3、在49.186机器上创建rabbitmq2容器,命令如下:
docker run -itd --name rabbitmq2 \
--hostname rabbitmq2 -p 4369:4369 \
-p 15672:15672 -p 5672:5672 \
-p 25672:25672 \
-v /data/rabbitmq/hosts:/etc/hosts \
-v /etc/localtime:/etc/localtime rabbitmq4、在49.83机器上创建rabbitmq3容器,命令如下:
docker run -itd --name rabbitmq3 \
--hostname rabbitmq3 -p 4369:4369 \
-p 15672:15672 -p 5672:5672 \
-p 25672:25672 \
-v /data/rabbitmq/hosts:/etc/hosts \
-v /etc/localtime:/etc/localtime rabbitmq5、将节点1容器中的.erlang.cookie拷贝到节点2和节点3的容器中,路径为:
docker cp rabbitmq1:/var/lib/rabbitmq/.erlang.cookie .
docker cp .erlang.cookie rabbitmq2:/var/lib/rabbitmq
docker cp .erlang.cookie rabbitmq3:/var/lib/rabbitmq
注:容器中的.erlang.cookie的属主和属组都要是rabbitmq才行,并且此文件的权限要设置为400,否则容器启动失败
6、接下来将rabbitmq2和rabbitmq3加入到rabbitmq1中,在rabbitmq2和rabbitmq3容器中执行如下命令:
rabbitmqctl stop_app #关闭RabbitMQ服务
rabbitmqctl reset #重置节点
rabbitmqctl join_cluster rabbit@rabbitmq1 #加入集群,rabbit@rabbitmq1为节点名
rabbitmqctl start_app #启动服务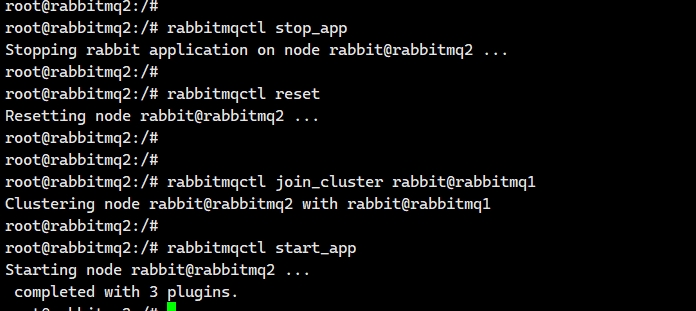
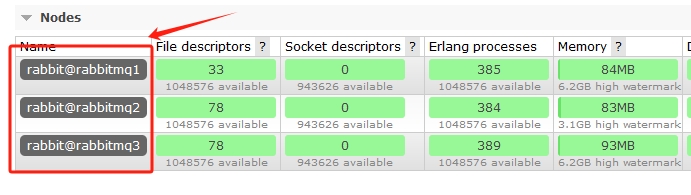
添加后,通过任意节点的管理端口15672访问,输入账号密码guest/guest,即可看到节点信息,如图:
如果rabbitmq的15672不通,说明管理插件没启动,可进入容器中执行命令启动,如下:
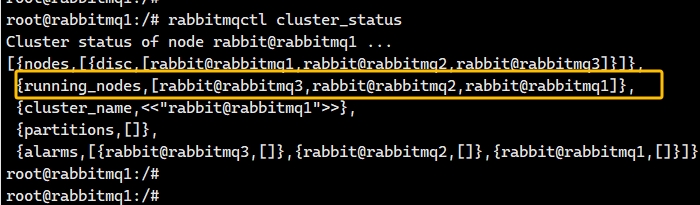
rabbitmq-plugins enable rabbitmq_management命令行查看集群状态:
注意几点:
- rabbitmqctl stop 会将Erlang虚拟机关闭,容器会挂掉
- rabbitmqctl stop_app 只关闭rabbitMQ服务
- rabbitmqctl start_app 只启动应用服务
- 节点必须重置后才能加入集群,重置节点会删除该节点上以前存在的所有资源和数据,保证空数据
集群自动发现机制:
如果集群中默认配置中启用了RabbitMQ的自动集群发现机制。那么在一个节点上创建Exchange或Queue时,它会自动地在整个集群中被发现,通过广播的机制,通过如下命令查看是否开启发现机制,如图:

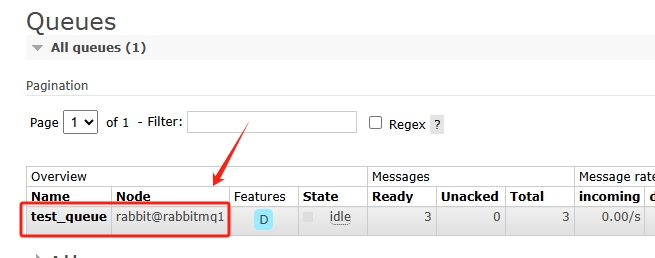
在rabbitmq1创建一个队列,在rabbitmq2和rabbitmq3上也是可以看到的,如图:
发送消息
Exchanges(交换器)和 Queues(队列)是两个核心组件,它们共同工作以实现消息的发送和接收
Queues(队列):
- 定义:队列是消息的存储位置,它们保持消息直到它们被消费者消费。队列可以被认为是一个消息的缓冲区
- FIFO:队列通常按照先进先出(FIFO)的顺序处理消息,尽管某些特性(如优先级队列)可能会影响这一点
- 持久性:队列可以被声明为持久化的,这意味着即使 RabbitMQ 服务器重启,队列中的消息也不会丢失
- 独占性:队列也可以是独占的,这意味着它们仅与创建它们的连接相关联,并且在连接关闭时会被删除
Exchanges(交换器):
- 定义:交换器充当消息的路由中心。生产者将消息发送到交换器,而不是直接发送到队列
- 路由逻辑:交换器根据类型和路由键将消息路由到一个或多个队列。交换器有几种类型,每种类型都有不同的路由逻辑:
- direct:根据路由键将消息直接路由到具有匹配键的队列
- fanout:将消息广播到所有绑定到该交换器的队列,忽略路由键
- topic:根据路由键模式匹配将消息路由到队列
- headers:根据消息的 headers 属性将消息路由到队列,忽略路由键
- 持久性:交换器也可以被声明为持久化的,这意味着服务器重启后交换器仍然存在
交换器和队列的工作流程:
- 声明队列:消费者或生产者首先声明一个队列,可以选择设置其属性,如持久性、独占性等
- 声明交换器:声明一个交换器,并设置其类型和持久性等属性
- 绑定队列到交换器:将队列绑定到交换器上,可以选择一个路由键,这定义了交换器如何将消息路由到该队列
- 发送消息:生产者发送消息到交换器,可以指定一个路由键
- 路由消息:交换器根据其类型和路由键将消息路由到一个或多个绑定的队列
- 消息消费:消费者从队列中消费消息,通常通过拉取(pull-based)或推模式(push-based)
下面演示下简单的发送消息
1、首先登录管理页面,创建队列(Queues),持久化方案选择持久(Durable),如图:
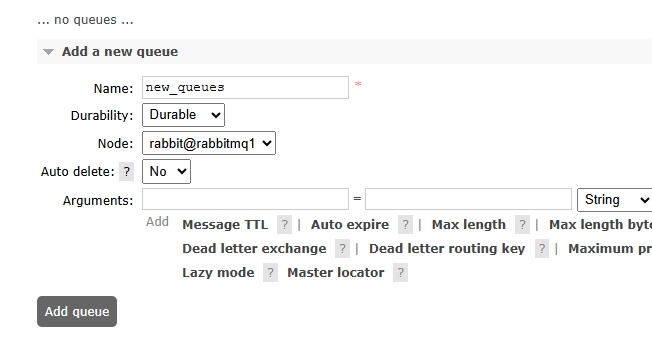
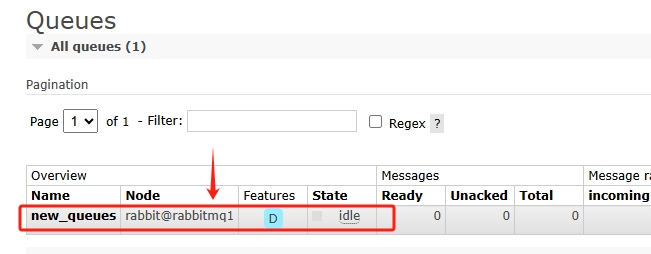
队列创建在了集群中的rabbitmq1节点上,如图:
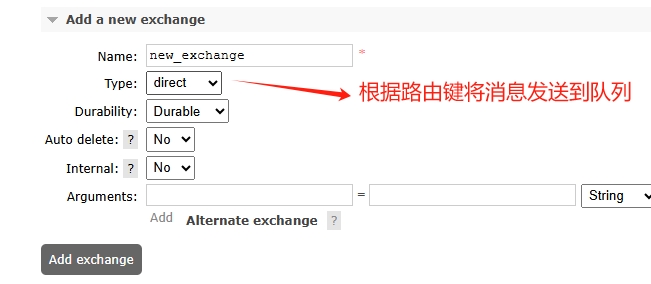
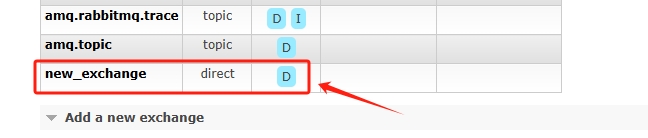
2、创建交换器(Exchanges),类型选择路由键,如图:
3、将交换器绑定到队列,点击刚才创建的交换器,点击Bindings,如图:
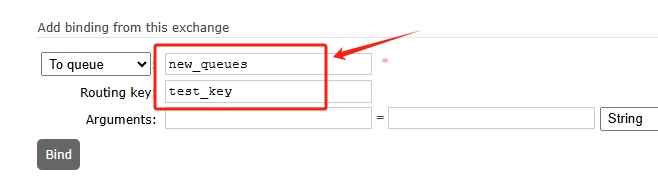
点击Bind后即可绑定成功,此时如果切换到Queues页面,点击刚才创建的队列,也可以看到绑定过来的交换器,如图:
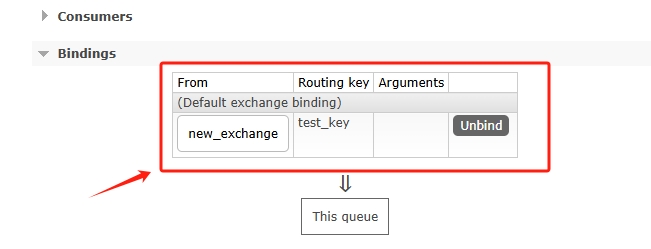
4、验证消息发送,点击创建的交换器new_chanage,下方有个Publish message,输入路由键,根据此路由键就能向绑定的队列发送消息,模式选择可持续,这样就能存在本地磁盘了,如图:
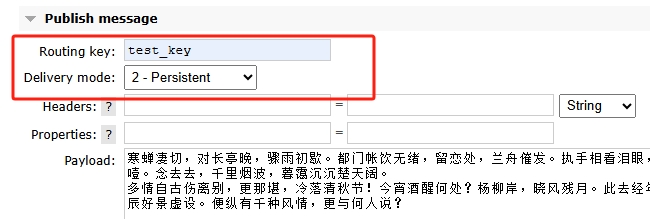
点击推送消息后,在队列页面可以看到Ready和Total已经显示有一条消息,如图:

登录rabbitmq1节点,在mnesia/rabbit@rabbitmq1/msg_stores/vhosts路径下可以看到创建的队列以及队列中消息,如图:
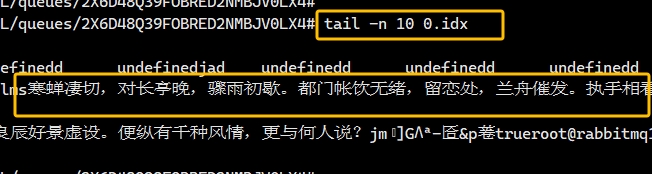
此时登录其他两个节点,可以发现并没有消息内容,因为虽然当前rabbitmq是集群,但是数据并没有做高可用同步,单个节点生产的消息只保留在了当前节点,没有同步到其他节点,此时如果这个节点挂了,数据就会消失,因此数据的高可用非常重要,看下面教程配置集群数据高可用
配置集群高可用
集群发现机制只是集群节点之前互相识别对方并通信,交换路由信息,以及协调队列和交换器等资源的分布,并不涉及数据复制,因此如果集群没有开启高可用策略,那么数据实际还是在当前节点存储,并没有同步到其他节点上,下面说下如何配置集群数据的高可用策略
1、登录任意节点,点击Admin–policies,如图:
设置策略名称,匹配模式,以及匹配范围,同步模式,如图:
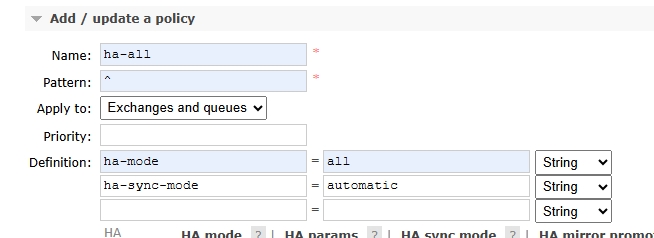
- pattern:匹配模式,^表示匹配所有
- ha-mode:设置镜像队列为all,此模式下,队列会在集群中的所有节点上进行镜像
- ha-sync-mode:同步模式,automatic表示自动同步,manual表示手动
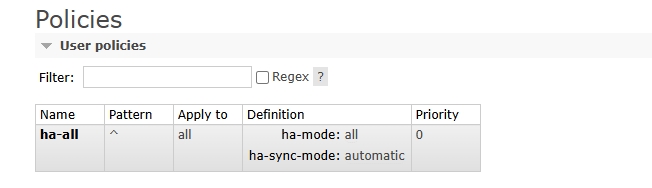
在管理界面可以看到已经配置的策略,如图:
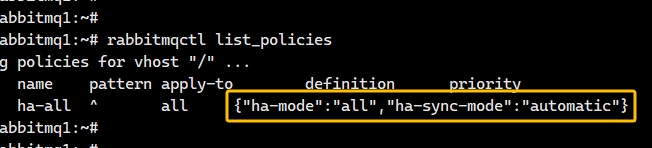
在命令行也可以看到创建的策略,如图:
设置完成后,观察其余两个节点,能看到mnesia目录下已经同步过来新的消息了
新增节点:按照上面的教程配置新节点,将新节点添加到集群后,数据也会自动同步到新节点
删除节点:删除节点很简单,首先停止要删除的节点上的rabbitmq,然后在其他节点执行如下命令:
rabbitmqctl forget_cluster_node rabbit@rabbitmq2 #删除节点2附加
如果通过NGINX代理rabbitmq,那么配置文件可以这样写:
location /rabbitmq/ {
port_in_redirect on;
proxy_redirect off;
proxy_pass http://xxx.xxx.xxx:15672/;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header User-Agent $http_user_agent;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
location ~* /rabbitmq/api/ {
rewrite ^ $request_uri;
rewrite ^/rabbitmq/api/(.*) /api/$1 break;
return 400;
proxy_pass http://xxx.xxx.xxx:15672$uri;
proxy_buffering off;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}这样配置后,在调用API设置权限的时候就不会出现Management API returned status code 405, 也可以避免出现The object you clicked on was not found; it may have been deleted on the server错误
rabbitmq队列导出导入
rabbitmq在使用过程中,有时会涉及到迁移,此时就需要将队列导入到新的mq中,同时把消息也更新到最新的mq中
1、导出队列(Queues)
首先登陆源mq,进入到主页中的Overview页面,如图:
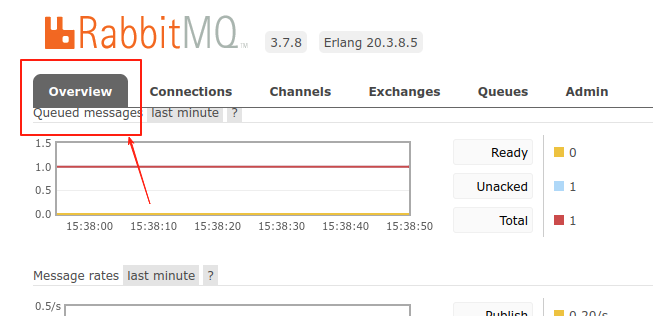
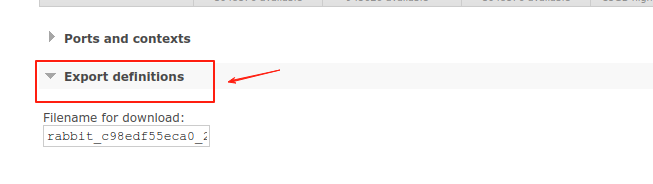
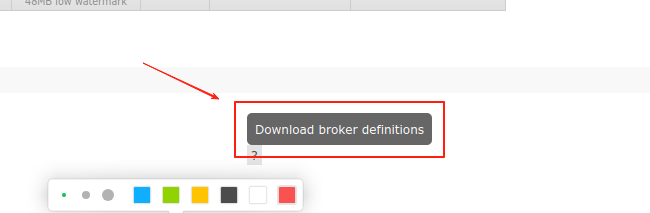
在主页面中找到,Export definitions,然后点击右侧的Download broker definitions,如图:
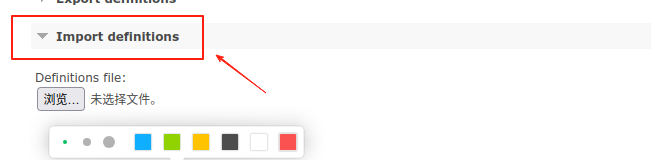
2、导入队列:
登陆目标mq中,也在主页面中,找到Import definitions,点击Upload broker definitions,如图:
rabbitmq消息数据备份与恢复
1、登陆到源服务器,执行rabbitmqctl命令,查看数据存储目录,如下:
rabbitmqctl eval 'rabbit_mnesia:dir().'
#/var/lib/rabbitmq/mnesia/rabbit@rabbitmq #本例子数据地址2、关闭源rabbitmq,防止数据不一致,如果容器运行的,直接执行如下:
docker stop rabbitmq 3、备份rabbitmq消息数据,直接使用tar命令打包即可,如下:
tar -zcvf rabbitmq.tgz /var/lib/rabbitmq/mnesia/rabbit@rabbitmq4、登陆到目标rabbitmq服务器,,然后将备份的数据解压到对应的目录即可,如下:
tar xf rabbitmq.tgz /var/lib/rabbitmq/mnesia注意:如果是容器方式运行的rabbitmq,要注意是否将mnesia目录挂在到外面来
4、修改数据目录权限(如果需要),命令如下:
chown rabbitmq:rabbitmq rabbit@rabbitmq5、启动目标服务器的rabbitmq,如下:
docker start rabbitmq 或 systemctl start rabbitmq常见命令
#查看队列数据但不删除
rabbitmqadmin -u username -p passwd get queue=queue-name ackmode=ack_requeue_true count=10
#查看队列数据并删除掉,区别在于ack_requeue_false还是true
rabbitmqadmin -u username -p passwd get queue=queue-name ackmode=ack_requeue_false count=10
#列出队列信息
rabbitmqadmin -u username -p passwd list queues name messages messages_ready messages_unacknowledgedrabbitmq问题
rabbitmq页面提示错误:
Network partition detected
Mnesia reports that this RabbitMQ cluster has experienced a network partition. There is a risk of losing data. Please read RabbitMQ documentation about network partitions and the possible s表明 RabbitMQ 集群发生了 网络分区(Network Partition),即集群中的节点之间失去了网络连接,导致数据可能不一致或丢失
解决方案:在rabbitmq.conf中i添加配置:
cluster_partition_handling = pause_minority配置pause_minority后,当发生网络分区时,RabbitMQ 会自动检测自身是否处于少数派(小于或等于集群中一半的节点数)。如果是少数派,则会自动暂停这些节点,直到网络分区结束,此配置可以保证数据一致性,防止脑裂现象,缺点是可能会导致部分节点不可用,需要网络恢复后手动或自动重启


